
- Graph Neural Networks (GNNs) are vital for analyzing complex data from e-commerce and social networks.
- As graph data grows, out-of-core solutions like DiskGNN become necessary to handle datasets exceeding memory limits.
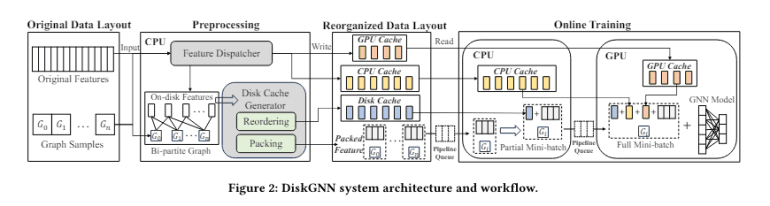
- DiskGNN optimizes training efficiency by minimizing unnecessary disk reads through innovative offline sampling.
- Its multi-tiered storage architecture, leveraging GPU/CPU memory and disk storage, accelerates training significantly.
- DiskGNN maintains high model accuracy while reducing average epoch time and disk access time.
- By organizing node features into contiguous blocks on disk, DiskGNN mitigates the typical proliferation of read operations in disk-based systems.
Main AI News:
Graph Neural Networks (GNNs) play a pivotal role in analyzing data from domains like e-commerce and social networks, managing intricate structures. Conventionally, GNNs handle data within a system’s primary memory. However, as graph data expands in scale, addressing datasets surpassing memory capacities becomes imperative, leading to the demand for out-of-core solutions where data resides on disk.
Despite the necessity, existing out-of-core GNN systems encounter challenges in balancing efficient data access with model accuracy. These systems often confront a dilemma: either endure sluggish input/output operations due to frequent, small disk reads or compromise accuracy by handling graph data in disjointed fragments. Pioneering solutions like Ginex and MariusGNN, while commendable, have struggled with these challenges, displaying notable drawbacks in either training speed or accuracy.
The DiskGNN framework, a collaborative effort by researchers from Southern University of Science and Technology, Shanghai Jiao Tong University, Centre for Perceptual and Interactive Intelligence, AWS Shanghai AI Lab, and New York University, emerges as a transformative solution tailored to enhance the speed and accuracy of GNN training on extensive datasets. This system employs an innovative offline sampling technique to prepare data for rapid access during training. By preprocessing and structuring graph data based on anticipated access patterns, DiskGNN minimizes superfluous disk reads, substantially augmenting training efficiency.
The architecture of DiskGNN revolves around a multi-tiered storage strategy that intelligently utilizes GPU and CPU memory in conjunction with disk storage. This setup ensures that frequently accessed data remains proximate to the computation layer, significantly expediting the training process. In benchmark assessments, DiskGNN showcased an acceleration of over eight times compared to baseline systems, with training epochs averaging approximately 76 seconds vis-à-vis 580 seconds for solutions like Ginex.
Performance evaluations further underscore DiskGNN’s effectiveness. The system not only accelerates the GNN training process but also upholds high model accuracy. For instance, in evaluations involving the Ogbn-papers100M graph dataset, DiskGNN either matched or surpassed the top model accuracies of existing systems while substantially curtailing average epoch time and disk access time. Specifically, DiskGNN maintained an accuracy of approximately 65.9% while reducing the average disk access time to just 51.2 seconds, in contrast to 412 seconds in prior systems.
DiskGNN’s design mitigates the typical proliferation of read operations inherent in disk-based systems. By organizing node features into contiguous blocks on the disk, the system averts the common scenario where each training step necessitates multiple, small-scale read operations. This not only alleviates the burden on the storage system but also diminishes the time spent awaiting data, thereby optimizing the overall training pipeline.
Conclusion:
The introduction of DiskGNN represents a significant advancement in large-scale learning, particularly for industries reliant on complex data analysis. Its ability to optimize training efficiency and maintain high accuracy levels sets a new standard in the market, promising enhanced performance and productivity for organizations dealing with extensive datasets.