
- HPT 1.5 Air revolutionizes AI by seamlessly integrating visual and textual data.
- Traditional models struggle to combine these data types efficiently, leading to inefficiencies.
- HyperGAI’s HPT 1.5 Air model overcomes these challenges with advanced multimodal capabilities.
- Built on the foundation of its predecessors, HPT 1.5 Air introduces significant enhancements.
- Utilizes the latest LLaMA 3 8B model for optimized efficiency and robustness.
- Despite its modest parameter count, the model delivers superior performance across various benchmarks.
- Outperforms larger models in environments requiring high visual and textual comprehension.
Main AI News:
In the realm of artificial intelligence, the fusion of visual and textual data marks a pivotal point in advancing systems akin to human perception. As AI progresses, the seamless integration of these data types emerges as a cornerstone for crafting more intuitive and impactful technologies.
The predominant challenge within this domain revolves around the imperative for models to adeptly process and decipher combined streams of visual and textual information. Traditionally, these streams have been treated as separate entities, resulting in inefficiencies and a discernible gap in achieving a fully integrated comprehension. This fragmentation often leads to a loss of context or subtlety, particularly in addressing intricate scenarios that demand a holistic perspective.
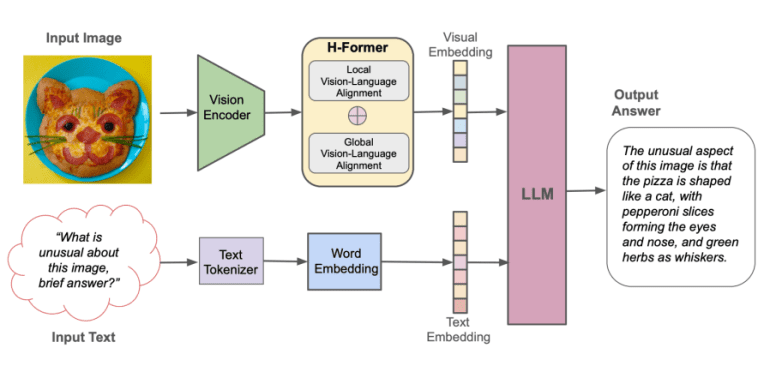
HyperGAI has recently made significant breakthroughs in surmounting these challenges through the development of the HPT 1.5 Air model. This innovative model stands as a testament to the forefront of multimodal AI advancements, seamlessly blending sophisticated visual encoding mechanisms with robust language processing capabilities. Notably, the HPT 1.5 Air builds upon the foundational architecture of its predecessors while introducing substantial enhancements in both its visual encoder and language model components.
Powered by the latest LLaMA 3 8B model iteration, the HPT 1.5 Air boasts optimized efficiency and robustness. Its remarkable architecture enables a comprehensive and nuanced understanding of multimodal inputs. Despite its relatively modest parameter count of just under 10 billion, the model remains agile and highly efficient, rivaling even larger, more parameterized competitors.
Across various benchmarks, the HPT 1.5 Air has showcased unparalleled performance. Surpassing its predecessors and larger counterparts, particularly in environments with elevated visual and textual comprehension demands, this model sets new benchmarks for what can be achieved with fewer than 10 billion parameters. In evaluations such as SEED-I, SQA, and MMStar, the HPT 1.5 Air not only meets but surpasses expectations, establishing itself as a trailblazer in the realm of multimodal AI.
Conclusion:
The introduction of HPT 1.5 Air, coupled with LLaMA 3 integration, represents a significant leap forward in the multimodal AI landscape. Its ability to seamlessly blend visual and textual data, coupled with optimized efficiency and superior performance, positions it as a game-changer in the market. As businesses increasingly rely on AI for complex tasks, solutions like HPT 1.5 Air offer unparalleled potential for innovation and competitive advantage.