
- Instruct-MusicGen redefines text-to-music editing with a novel AI approach.
- Developed collaboratively by researchers from C4DM, Queen Mary University of London, Sony AI, and Music X Lab, MBZUAI.
- Addresses challenges of traditional methods by leveraging pre-trained models.
- Introduces text fusion and audio fusion modules to enhance MusicGen architecture.
- Achieves superior performance with minimal additional parameters and reduced training time.
- Outperforms existing baselines in audio quality, alignment with textual descriptions, and signal-to-noise ratio improvements.
Main AI News:
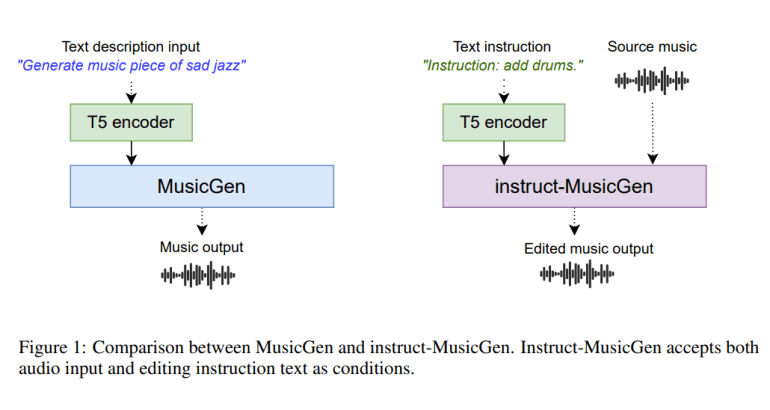
In the realm of music composition and editing, the fusion of textual commands with musical expression has long been a formidable challenge. Traditional methods often necessitate the training of bespoke models from the ground up, resulting in resource-intensive processes and suboptimal outcomes. However, a groundbreaking solution has emerged from the collaborative efforts of researchers at C4DM, Queen Mary University of London, Sony AI, and Music X Lab, MBZUAI – Instruct-MusicGen.
This innovative approach represents a paradigm shift in text-to-music editing, offering a seamless integration of textual directives with musical compositions. Gone are the days of cumbersome model training and imprecise audio reconstructions. Instruct-MusicGen streamlines the process, leveraging pre-trained models to achieve unparalleled results.
At its core, Instruct-MusicGen introduces two key enhancements: the text fusion module and the audio fusion module. These modules expand upon the original MusicGen architecture, empowering it to process both textual instructions and audio inputs concurrently. The text fusion module modifies the behavior of the text encoder, enabling the model to interpret and execute text-based editing commands with precision. Meanwhile, the audio fusion module allows for seamless integration of external audio inputs, facilitating accurate audio editing.
In a testament to its efficiency, Instruct-MusicGen boasts remarkable performance with minimal additional parameters – a mere 8% increase compared to the original MusicGen model. Furthermore, the training process is completed within a fraction of the time, requiring only 5,000 steps. This optimized approach not only reduces resource usage but also enhances overall productivity.
The effectiveness of Instruct-MusicGen is evidenced by its superior performance across various tasks, as demonstrated on both the Slakh test set and the out-of-domain MoisesDB dataset. It surpasses existing baselines in terms of audio quality, alignment with textual descriptions, and signal-to-noise ratio improvements. Instruct-MusicGen represents a significant advancement in the field of text-to-music editing, paving the way for a new era of AI-driven musical creativity.
Conclusion:
The introduction of Instruct-MusicGen marks a significant advancement in the text-to-music editing landscape. Its streamlined approach, coupled with superior performance metrics, indicates a promising future for AI-driven musical creativity. This innovation has the potential to revolutionize the market by offering efficient and precise solutions to longstanding challenges in music composition and editing.