
TL;DR:
- Researchers from TH Nürnberg and Apple introduced a multimodal model for virtual assistants.
- The model combines audio and linguistic data without the need for trigger phrases.
- It aims to create more natural and intuitive user-virtual assistant interactions.
- The system is resource-efficient and adaptable for various devices.
- Achieves lower error rates and better performance with minimal training data.
- Specialized low-dimensional audio representations enhance user intent detection.
Main AI News:
The world of virtual assistants has encountered a pivotal challenge: how to infuse interactions with a sense of naturalness and intuitiveness. Gone are the days when a specific trigger phrase or a button press was the requisite precursor to issuing a command. Such interruptions disrupted the fluidity of conversation and eroded the user experience. The crux of the issue lies in the assistant’s knack for discerning its own name amidst a cacophony of background noises and conversations. Moreover, distinguishing between directed speech meant for the device and non-directed address, which isn’t device-oriented, remains a formidable hurdle.
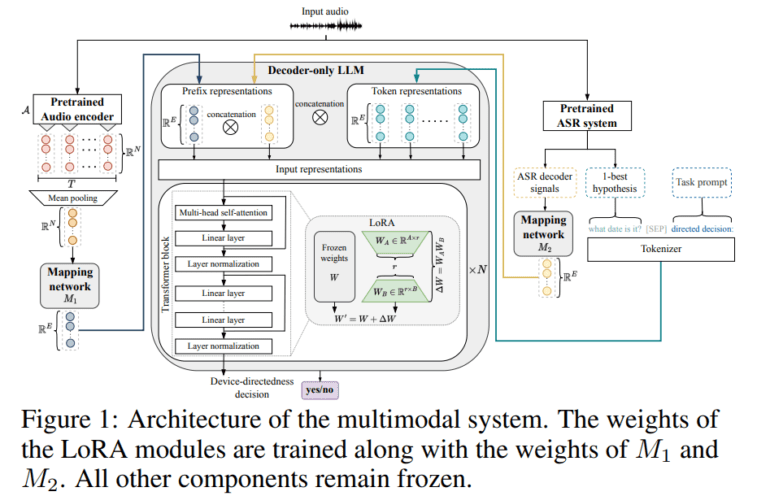
Traditionally, virtual assistant interactions have hinged on the need for a trigger phrase or a button press before a command is executed. While functional, this approach disrupts the organic flow of conversation. In a striking departure from this norm, a pioneering research team comprising experts from TH Nürnberg and Apple has unveiled a groundbreaking solution. Their innovation revolves around a multimodal model that capitalizes on Large Language Models (LLMs) and fuses decoder signals with audio and linguistic cues. This ingenious approach adeptly discriminates between directed and non-directed audio, all without the reliance on a trigger phrase.
At its core, this ingenious solution aims to usher in a seamless era of user-virtual assistant interactions. The model, meticulously crafted by the researchers, possesses the ability to interpret user commands with a heightened sense of intuition, thanks to its integration of advanced speech detection techniques. This breakthrough marks a monumental stride in the realm of human-computer interaction, with the ultimate goal of delivering a more natural and user-centric experience through virtual assistants.
The proposed system harnesses acoustic features extracted from a pre-trained audio encoder, harmoniously blending them with 1-best hypotheses and decoder signals derived from an automatic speech recognition system. These amalgamated elements serve as the input features for a meticulously engineered large language model. Notably, this model has been designed to operate with data and resource efficiency in mind, demanding minimal training data and catering to devices with constrained resources. Remarkably, even when paired with a solitary frozen LLM, it continues to function with remarkable adaptability and efficiency across a spectrum of device environments.
In terms of performance, the results obtained by the researchers paint a compelling picture. This multimodal approach boasts lower equal-error rates compared to its unimodal counterparts, all while requiring significantly less training data. The study reveals that specialized low-dimensional audio representations outperform their high-dimensional counterparts, underscoring the model’s efficacy in deciphering user intent with resource efficiency at its core.
Conclusion:
The collaboration between TH Nürnberg and Apple has introduced a game-changing multimodal model that promises to enhance virtual assistant interactions. This innovation not only eliminates the need for trigger phrases but also offers resource efficiency and improved performance. For the market, this means a potential shift towards more seamless and user-friendly virtual assistant experiences, opening up opportunities for improved human-computer interaction solutions and increased user adoption.