
- Transformer architecture’s adaptation into Vision Transformers (ViTs) has sparked interest in Computer Vision (CV) community.
- ViTs segment images into patches, convert them into tokens and utilize Multi-Head Self-Attention (MHSA).
- Challenges include handling variable input resolutions and integrating with self-supervised frameworks.
- Recent solution: Vision Transformer with Any Resolution (ViTAR), featuring Adaptive Token Merger (ATM) and Fuzzy Positional Encoding (FPE).
- ViTAR efficiently processes high-resolution images with minimal computational burden.
- Experiments validate ViTAR’s superiority in performance and versatility across visual tasks.
Main AI News:
The impressive advancements achieved by the Transformer architecture in the realm of Natural Language Processing (NLP) have sparked considerable interest within the Computer Vision (CV) community. This adaptation of the Transformer into vision tasks, known as Vision Transformers (ViTs), involves segmenting images into non-overlapping patches, converting each patch into tokens, and subsequently employing Multi-Head Self-Attention (MHSA) to capture inter-token dependencies.
Capitalizing on the robust modeling capabilities inherent in Transformers, ViTs have showcased remarkable performance across a wide array of visual tasks, including image classification, object detection, vision-language modeling, and even video recognition. Nevertheless, despite their successes, ViTs face challenges in real-world scenarios, particularly in handling variable input resolutions, often resulting in significant performance degradation.
In response to this challenge, recent endeavors such as ResFormer (Tian et al., 2023) have emerged. These initiatives incorporate multiple-resolution images during training and refine positional encodings into more adaptable, convolution-based formats. However, further enhancements are necessary to ensure sustained high performance across varying resolutions and seamless integration into prevalent self-supervised frameworks.
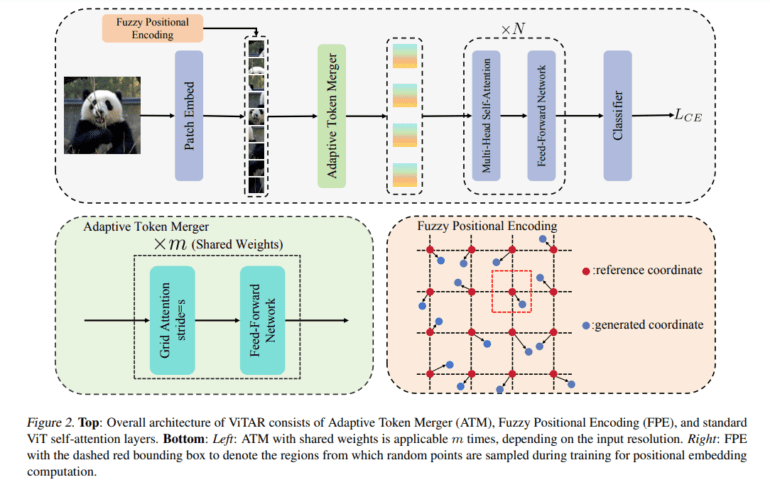
Addressing these challenges head-on, a pioneering research team from China proposes an innovative solution, Vision Transformer with Any Resolution (ViTAR). This groundbreaking architecture is engineered to process high-resolution images with minimal computational overhead while demonstrating robust resolution generalization capabilities. Central to ViTAR’s effectiveness is the introduction of the Adaptive Token Merger (ATM) module, which iteratively processes tokens post-patch embedding, efficiently merging tokens into a fixed grid shape, thereby enhancing resolution adaptability while mitigating computational complexity.
Moreover, to facilitate generalization to arbitrary resolutions, the researchers introduce Fuzzy conditional encoding (FPE), which introduces positional perturbation. This transformation converts precise positional perception into a fuzzy one with random noise, thereby preventing overfitting and enhancing adaptability.
The contributions of their study extend to the proposal of an effective multi-resolution adaptation module (ATM), which significantly enhances resolution generalization and reduces computational load under high-resolution inputs. Additionally, the introduction of Fuzzy Positional Encoding (FPE) enables robust position perception during training, improving adaptability to varying resolutions.
Extensive experiments conducted by the research team unequivocally validate the efficacy of the proposed approach. The base model not only demonstrates robust performance across a range of input resolutions but also exhibits superior performance compared to existing ViT models. Furthermore, ViTAR showcases commendable performance in downstream tasks such as instance segmentation and semantic segmentation, underscoring its versatility and utility across diverse visual tasks.
Conclusion:
The introduction of Vision Transformer with Any Resolution (ViTAR) represents a significant leap in addressing the challenges faced by Vision Transformers (ViTs) in adapting to variable input resolutions. ViTAR’s innovative features, such as the Adaptive Token Merger (ATM) and Fuzzy Positional Encoding (FPE), not only enhance resolution adaptability but also minimize computational complexity. This breakthrough promises to revolutionize the market by enabling more efficient and versatile solutions for various visual tasks, thus opening up new opportunities for advancement and application in the field of Computer Vision.