
TL;DR:
- LucidDreamer is an innovative AI pipeline developed by Seoul National University for creating high-quality 3D scenes in mixed reality.
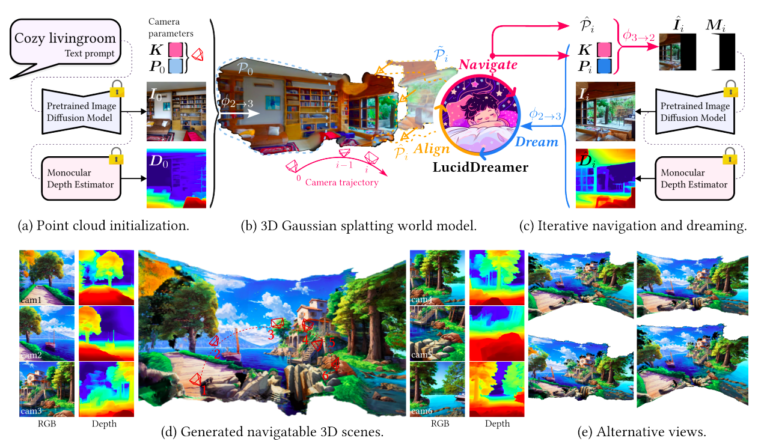
- It utilizes 3D Gaussian splatting and stable diffusion to generate diverse 3D scenarios from inputs like text, RGB, and RGBD.
- The process involves Dreaming and Alignment steps, creating geometrically consistent images in 3D space.
- LucidDreamer’s continuous representation of 3D Gaussian splats eliminates depth gaps, resulting in exceptionally photorealistic scenes.
- Figure 1 demonstrates impressive results, outperforming existing models across datasets.
- LucidDreamer supports various scene genres, permits text and image input combination, and allows input condition modification.
- This breakthrough in 3D scene generation has significant implications for industries reliant on computer vision and mixed reality technologies.
Main AI News:
In the realm of computer vision, the demand for high-quality 3D scenes has surged alongside the growth of mixed reality platforms and the rapid advancement of 3D graphics technology. The challenge lies in the ability to seamlessly transform various inputs, such as text, RGB, and RGBD images, into diverse and lifelike 3D scenarios. While previous efforts have explored constructing 3D objects and landscapes using diffusion models in voxel, point cloud, and implicit neural representations, they often fell short in terms of diversity and quality, primarily due to limitations in training data derived from 3D scans.
One promising solution involves harnessing the power of pre-trained picture-generating diffusion models, like Stable Diffusion. These models leverage extensive training data to produce convincing images but struggle to ensure multi-view consistency among the generated images. Enter LucidDreamer, a groundbreaking pipeline introduced by the research team at Seoul National University.
LucidDreamer employs a combination of 3D Gaussian splatting and stable diffusion, making it possible to generate a wide array of high-quality 3D scenes from various inputs, including text, RGB, and RGBD. The process involves two key steps: Dreaming and Alignment, which are iteratively performed to construct a unified, comprehensive point cloud.
The journey begins with an initial point cloud generated from the original image and its corresponding depth map. This point cloud serves as the foundation for creating geometrically consistent images, which are then projected into three-dimensional space. To ensure seamless integration into the new camera coordinate system, the research team guides the camera along a predefined trajectory.
Subsequently, the projected image undergoes inpainting through the Stable Diffusion-based network, resulting in a complete conceptualization of the scene. Lifting the inpainted image and its predicted depth map into 3D space creates a fresh set of 3D points. These points are delicately adjusted within the 3D space, employing a suggested alignment technique that seamlessly connects them to the existing point cloud. The cumulative result of these processes yields an extensive point cloud, which serves as the foundation for optimizing the Gaussian splats.
What sets LucidDreamer apart is its continuous representation of 3D Gaussian splats, which effectively eliminates gaps caused by depth discrepancies within the point cloud. The outcome? A strikingly photorealistic 3D environment that surpasses existing models in terms of visual impact and realism.
Figure 1 showcases the impressive capabilities of LucidDreamer alongside its straightforward implementation. Notably, LucidDreamer consistently delivers astonishingly lifelike results across all datasets, surpassing its counterparts when generating 3D scenes conditioned on input from ScanNet, NYUDepth, and Stable Diffusion.
But LucidDreamer’s prowess extends beyond realism; it thrives in versatility. This model can craft 3D scenes spanning various genres, from realistic to anime and Lego-inspired to outdoor/indoor settings. What’s more, it seamlessly accommodates multiple input conditions, allowing for text and images to be combined effortlessly. This not only simplifies scene creation but also opens doors for creative exploration by enabling input condition modification throughout the 3D space creation process.
Conclusion:
LucidDreamer, with its fusion of 3D Gaussian splatting and stable diffusion, stands as a transformative force in the domain of domain-free 3D scene generation. Its ability to produce diverse, high-quality 3D scenes from a range of inputs showcases its potential to revolutionize industries reliant on computer vision and mixed reality technologies. With LucidDreamer, the future of 3D scene generation has never looked more promising.