
TL;DR:
- COSMO, a new multimodal AI framework, addresses challenges in integrating diverse data types like text and images or videos.
- Developed by Microsoft and National University of Singapore researchers, COSMO partitions language models for efficient data processing.
- It introduces a contrastive loss mechanism to enhance alignment between textual and visual data.
- COSMO leverages the Howto-Interlink7M dataset for improved performance in image-text tasks.
- In a 4-shot Flickr captioning task, COSMO showed a significant performance boost from 57.2% to 65.1%.
Main AI News:
Multimodal learning is a frontier where the fusion of visual and textual data presents both challenges and opportunities for AI advancement. A profound obstacle in this arena lies in harmonizing disparate data types, like text and images or videos, to enable AI systems to glean nuanced insights simultaneously. This hurdle is pivotal in propelling AI towards a more human-like comprehension and interaction with the world.
Recent strides in this direction have predominantly relied on Large Language Models (LLMs) for their adeptness in processing vast textual inputs. However, these models grapple with tasks that require precise alignment between textual and visual elements. Bridging this gap, the COSMO framework (COntrastive Streamlined MultimOdal Model), a collaborative creation of researchers from the National University of Singapore and Microsoft Azure AI, emerges as a groundbreaking solution in the realm of multimodal data processing.
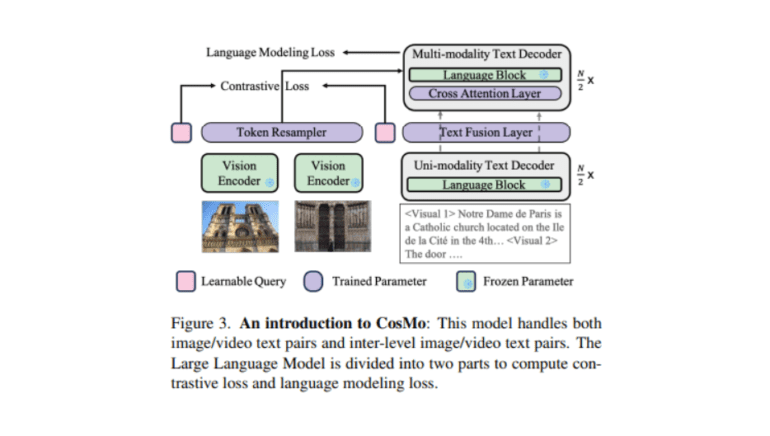
COSMO pioneers a strategic approach by segmenting the language model into dedicated units for handling unimodal text and versatile multimodal data. This division enhances the model’s efficiency and effectiveness in managing diverse data types. Moreover, COSMO introduces a contrastive loss mechanism into the language model, addressing the challenge of aligning different data forms, especially in tasks involving textual and visual data.
Integral to COSMO’s methodology is its reliance on the Howto-Interlink7M dataset, a trailblazing resource in the field. This dataset offers meticulous annotations of video-text data, filling a critical void in the availability of high-quality, extensive video-text datasets. Its comprehensive nature significantly elevates the model’s performance in image-text tasks.
COSMO’s performance speaks volumes about its innovative design and methodology. It delivers substantial improvements over existing models, particularly in tasks that demand precise alignment between textual and visual data. In a specific 4-shot Flickr captioning task, COSMO’s performance soared from 57.2% to 65.1%. This remarkable leap underscores the model’s enhanced capacity to comprehend and process multimodal data, marking a significant stride in the world of AI.
Conclusion:
The COSMO framework represents a major breakthrough in the field of multimodal AI processing. Its ability to efficiently handle diverse data types and improve alignment between textual and visual data opens up exciting possibilities for industries reliant on image and video analysis, such as marketing, e-commerce, and content creation. COSMO’s innovative approach is poised to drive advancements in these sectors, enhancing the capabilities of AI systems and leading to more sophisticated and accurate data interpretation.