
- Large Language Models (LLMs) often offer confident responses, raising concerns about reliability, especially for factual queries.
- Existing methods to assess LLM response trustworthiness are lacking, prompting the need for standardized metrics.
- VISA researchers propose a novel method based on harmoniticity analysis to evaluate LLM response robustness in real-time.
- The method, denoted as γ, correlates positively with false or misleading answers, offering a model-agnostic approach.
- Empirical validation across LLM models and domains highlights lower γ values for larger models, indicating higher trustworthiness.
Main AI News:
In today’s landscape, Large Language Models (LLMs) are frequently lauded for their confident responses to inquiries, yet this has spurred concerns regarding their reliability, particularly concerning factual accuracy. Despite the prevalence of uncertain or misleading content generated by LLMs, there remains a glaring absence of standardized methods for gauging the trustworthiness of their responses. This deficit leaves users without a definitive metric for assessing the reliability of LLM-generated information, necessitating further research or verification efforts. The ultimate goal is for LLMs to consistently yield high trust scores, thereby alleviating the need for extensive user validation procedures.
The assessment of LLMs has emerged as a critical endeavor, pivotal in evaluating model performance and adaptability to varying inputs, both essential factors for real-world applications. The FLASK method, for instance, stands out as a valuable tool for evaluating the consistency of LLMs across diverse stylistic inputs, with a particular emphasis on alignment capabilities to facilitate precise model evaluation. However, concerns persist regarding the susceptibility of model-graded evaluations to vulnerabilities, casting doubts on their reliability. These challenges underscore the importance of developing methodologies aimed at bolstering zero-shot robustness, particularly in light of the difficulties in maintaining performance across rephrased instructions.
The PromptBench framework exemplifies one such approach, systematically assessing LLM resilience to adversarial prompts while emphasizing the necessity of comprehending model responses to input variations. Recent studies have delved into the efficacy of introducing noise to prompts as a means of evaluating LLM robustness, advocating for unified frameworks and privacy-preserving prompt learning techniques. Mitigating LLM vulnerabilities to noisy inputs, especially within high-stakes contexts, highlights the criticality of ensuring consistent predictions. Methods for quantifying LLM confidence, including black-box and reflection-based approaches, are gaining traction, with the NLP literature emphasizing the enduring sensitivity of LLMs to perturbations, thereby reinforcing the ongoing importance of studies focused on input robustness.
In a groundbreaking initiative, researchers from VISA have introduced an innovative methodology for assessing the real-time robustness of any black-box LLM, with a keen focus on both stability and explainability. This approach hinges on measuring local deviations from harmoniticity, denoted as γ, offering a model-agnostic and unsupervised mechanism for evaluating response robustness. Human annotation experiments conducted by the researchers have revealed a positive correlation between γ values and the prevalence of false or misleading answers. Additionally, the utilization of stochastic gradient ascent along the gradient of γ has proven to be an efficient strategy for identifying adversarial prompts, thereby underscoring the effectiveness of the proposed methodology. This work represents an extension of the Harmonic Robustness methodology, originally developed to assess the robustness of predictive machine learning models, to the realm of LLMs.
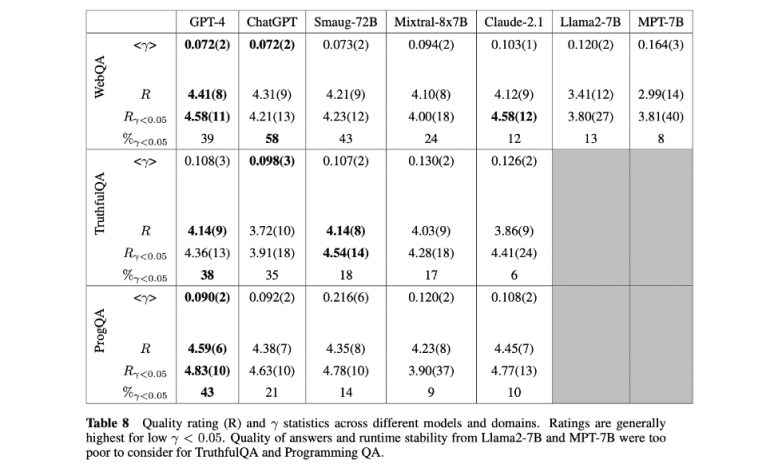
The researchers have outlined an algorithm for computing γ, a metric indicative of robustness, concerning inputs to LLMs. This method calculates the angle between the average output embedding of perturbed inputs and the original output embedding. Human annotation experiments further substantiate the correlation between γ values and the occurrence of false or misleading responses. Examples provided in the study illustrate the stability of GPT-4 outputs under perturbations, with γ = 0 signifying stable responses. However, minor grammatical deviations result in small, non-zero γ values, indicative of trustworthy responses. Conversely, significant variations yield higher γ values, suggesting decreased trustworthiness, albeit not necessarily indicative of incorrectness. The researchers advocate for empirical validation across models and domains to elucidate the correlation between γ and trustworthiness.
Furthermore, the researchers have undertaken an extensive analysis to ascertain the correlation between γ values, LLM robustness, and trustworthiness across a diverse array of LLMs and question-answer (QA) corpora. Noteworthy LLMs evaluated include GPT-4, ChatGPT, Claude 2.1, Mixtral-8x7B, and Smaug-72B, alongside older, smaller models such as Llama2-7B and MPT-7B. Three distinct QA corpora, namely Web QA, TruthfulQA, and Programming QA, were considered to encapsulate varying domains. Human annotators rated the truthfulness and relevance of LLM responses using a standardized 5-point scale, with Fleiss’ Kappa indicating consistent inter-annotator agreement. Generally, γ values below 0.05 corresponded to trustworthy responses, while escalating γ values tended to correlate with diminished quality, albeit within model and domain-specific contexts. Larger LLMs exhibited lower γ values, indicative of heightened trustworthiness, with GPT-4 consistently demonstrating superior quality and certified trustworthiness.
Conclusion:
The development of a novel method by VISA researchers to assess Large Language Model (LLM) trustworthiness through harmoniticity analysis offers a promising avenue for addressing concerns surrounding reliability. As market demands for accurate and trustworthy AI-driven responses continue to grow, such methodologies could play a crucial role in enhancing consumer confidence and facilitating the adoption of LLM technologies across various sectors. Additionally, the findings underscore the importance for LLM developers and providers to prioritize robustness and reliability in their offerings to meet evolving market expectations.