
TL;DR:
- Large language models (LLMs) face challenges with multistep reasoning, math, and staying updated.
- Automated Reasoning and Tool Usage (ART) framework leverages LLMs and tools for sophisticated reasoning.
- ART creates decompositions for new tasks, utilizes a task library, and selects the best tools at each stage.
- ART outperforms computer-generated reasoning chains by over 22% and achieves an average boost of 12.3% with tool usage.
- It surpasses direct few-shot prompting by 10.8% and outperforms GPT3 by 6.1% in mathematical and algorithmic reasoning.
- Updatable task and tool libraries enhance human-AI collaboration and improve performance on diverse tasks.
Main AI News:
In the rapidly evolving landscape of artificial intelligence, large language models (LLMs) have emerged as powerful tools capable of adapting to new tasks through in-context learning. By providing these models with a few demonstrations and real language instructions, they can quickly grasp the essence of a task without the need for extensive training data or annotations. However, challenges arise when it comes to multistep reasoning, mathematical computations, staying up-to-date with the latest information, and other complex tasks. Recent studies have proposed equipping LLMs with access to specialized tools to enhance their reasoning capabilities or training them to emulate a chain of reasoning for multistep problems, thereby addressing these limitations. Yet, adapting existing approaches to incorporate tool usage and chained reasoning into new activities remains a formidable task, requiring fine-tuning and prompt engineering tailored to specific tasks and tools.
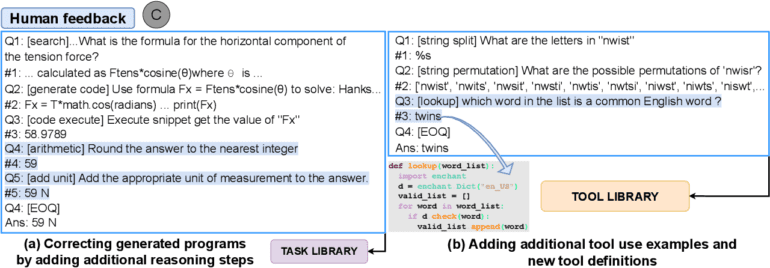
A collaborative effort between researchers from the University of Washington, Microsoft, Meta, the University of California, and the Allen Institute of AI has resulted in the development of Automated Reasoning and Tool Usage (ART), a groundbreaking framework designed to automate the creation of decompositions (multistep reasoning) for a wide range of tasks. This novel approach, presented in their recent study, leverages a task library to pull examples of similar tasks, enabling ART to generate decompositions and leverage tools efficiently, even with limited examples (Figure 1). To ensure flexibility and ease of comprehension, these examples employ a structured query language that facilitates the interpretation of intermediate stages, while also allowing users to pause the process and utilize external tools before seamlessly resuming the reasoning process once the tool outputs have been incorporated.
One of the key strengths of ART lies in its ability to provide the large language model with demonstrations on how to break down instances of various related activities, as well as guidance on selecting and employing tools from a dedicated tool library featured in these examples. By learning from these demonstrations, the model becomes adept at generalizing from known examples to effectively decompose new tasks and identify the most suitable tools for the job, without any explicit training. Moreover, users have the flexibility to update the task and tool libraries, incorporating recent examples to rectify logic errors or introduce new tools that align with the task at hand.
To evaluate the effectiveness of ART, the researchers created a comprehensive task library consisting of 15 BigBench tasks. They put ART to the test on 19 previously unseen BigBench tasks, 6 MMLU tasks, and a variety of tasks from relevant research on tool usage, including SQUAD, TriviaQA, SVAMP, and MAWPS. Remarkably, ART consistently outperformed computer-generated CoT reasoning chains on 32 out of 34 BigBench problems and all MMLU tasks, achieving an average improvement of over 22 percentage points. Furthermore, when leveraging tools, the performance on test tasks witnessed an average boost of approximately 12.3 percentage points compared to scenarios without tool usage.
On average, ART surpassed direct few-shot prompting approaches by an impressive 10.8% percentage points in both BigBench and MMLU tasks. For unseen tasks requiring mathematical and algorithmic reasoning, ART outshined direct few-shot prompting by an astounding 12.5%. Additionally, ART demonstrated superior performance compared to the best-known findings of GPT3, even when considering supervision for decomposition and tool usage, achieving a significant lead of 6.1% percentage points. The ability to update task and tool libraries with new examples fosters human interaction and enhances the reasoning process, enabling ART to achieve remarkable performance improvements on any given task with minimal human input. In fact, on 12 test tasks, ART outperformed the best-known GPT3 results by an average margin exceeding 20% points when provided with additional human feedback.
Conclusion:
The Automated Reasoning and Tool Usage (ART) framework represents a significant breakthrough for reasoning programs. By integrating large language models with automated tool usage, ART enhances reasoning capabilities and achieves remarkable performance improvements. This development opens up new possibilities for the market, enabling AI-driven solutions to excel in diverse industries and problem domains. The ability to adapt and update task and tool libraries facilitates human-AI collaboration, promising a future where AI systems can tackle complex tasks with minimal human input and deliver unprecedented results. The market can expect an acceleration in the adoption and utilization of ART-powered reasoning programs, leading to enhanced efficiency, productivity, and problem-solving capabilities in various business domains.