
TL;DR:
- BeLFusion is a novel approach in Human Motion Prediction (HMP) that focuses on Stochastic HMP, predicting the distribution of possible future motions.
- It introduces behavioral latent space and latent diffusion models to generate diverse and contextually appropriate human motion sequences.
- BeLFusion disentangles behavior from motion, resulting in more realistic and coherent motion predictions compared to state-of-the-art methods.
- Experimental evaluation shows impressive generalization capabilities on challenging datasets, outperforming other methods in accuracy metrics.
- BeLFusion’s potential applications include robotics, virtual reality, animation, and human-computer interaction.
Main AI News:
As the world remains captivated by the continuous advancements in Artificial Intelligence (AI), one remarkable application stands out at the intersection of computer vision and AI – Human Motion Prediction (HMP). This captivating task involves forecasting the future motion or actions of human subjects based on observed motion sequences. The goal is to predict how a person’s body poses or movements will evolve over time. With applications in robotics, virtual avatars, autonomous vehicles, and human-computer interaction, HMP has become an essential field of study.
An extension of traditional HMP, Stochastic HMP, focuses on predicting the distribution of possible future motions rather than a single deterministic outcome. This approach acknowledges the inherent spontaneity and unpredictability of human behavior, aiming to capture the uncertainty associated with future actions or movements. By considering the distribution of potential future motions, Stochastic HMP leads to more realistic and flexible predictions, particularly valuable in scenarios where anticipating multiple possible behaviors is crucial, such as assistive robotics or surveillance applications.
To achieve Stochastic HMP, generative models like GANs or VAEs have been utilized to predict multiple future motions for each observed sequence. However, this emphasis on generating diverse motions in the coordinate space has led to unrealistic and fast motion-divergent predictions, often misaligned with the observed motion. Additionally, these methods tend to overlook the anticipation of diverse low-range behaviors with subtle joint displacements. There is a clear need for new approaches that consider behavioral diversity and produce more realistic predictions in Stochastic HMP tasks.
In response to the limitations of existing methods, researchers from the University of Barcelona and the Computer Vision Center have proposed a groundbreaking solution – BeLFusion. This novel approach introduces a behavioral latent space to generate realistic and diverse human motion sequences.
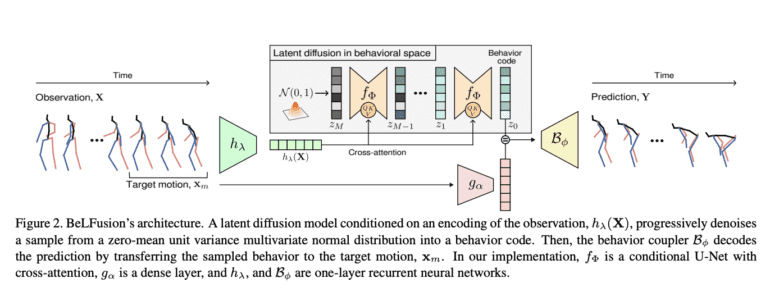
The core objective of BeLFusion is to disentangle behavior from motion, enabling smoother transitions between observed and predicted poses. This is achieved through a Behavioral VAE, comprising a Behavior Encoder, Behavior Coupler, Context Encoder, and Auxiliary Decoder. The Behavior Encoder combines a Gated Recurrent Unit (GRU) and 2D convolutional layers to map joint coordinates to a latent distribution. The Behavior Coupler then transfers the sampled behavior to ongoing motion, resulting in diverse and contextually appropriate motions. BeLFusion also incorporates a conditional Latent Diffusion Model (LDM) to accurately encode behavioral dynamics and effectively transfer them to ongoing motions, while minimizing latent and reconstruction errors, ultimately enhancing diversity in the generated motion sequences.
Continuing with its innovative architecture, BeLFusion features an Observation Encoder, an autoencoder that generates hidden states from joint coordinates. The model leverages the Latent Diffusion Model (LDM), employing a U-Net with cross-attention mechanisms and residual blocks to sample from a latent space where behavior is disentangled from pose and motion. By promoting diversity from a behavioral perspective and maintaining consistency with the immediate past, BeLFusion excels in producing significantly more realistic and coherent motion predictions compared to state-of-the-art methods in Stochastic HMP. Through its unique combination of behavioral disentanglement and latent diffusion, BeLFusion represents a promising advancement in human motion prediction, offering the potential to generate more natural and contextually appropriate motions for a wide range of applications.
Experimental evaluation demonstrates the impressive generalization capabilities of BeLFusion, performing remarkably well in both seen and unseen scenarios. It outperforms state-of-the-art methods across various metrics in a cross-dataset evaluation, demonstrating its effectiveness on challenging datasets like Human3.6M and AMASS. On H36M, BeLFusion achieves an Average Displacement Error (ADE) of approximately 0.372 and a Final Displacement Error (FDE) of around 0.474. Meanwhile, on AMASS, it boasts an ADE of roughly 1.977 and an FDE of approximately 0.513. These results underscore BeLFusion’s superior ability to generate accurate and diverse predictions, showcasing its effectiveness and generalization capabilities for realistic human motion prediction across different datasets and action classes.
Conclusion:
BeLFusion’s introduction of a behavioral latent space and latent diffusion models in Human Motion Prediction represents a significant advancement in the market. By addressing the limitations of existing methods, it offers more realistic and diverse motion predictions, enhancing its potential applications across various industries, such as robotics, virtual reality, and animation. Its superior generalization capabilities further position BeLFusion as a cutting-edge solution in the growing field of AI-driven human motion prediction. Businesses and industries seeking to leverage accurate and contextually appropriate motion predictions should keep a close eye on BeLFusion’s development and integration possibilities.