
TL;DR:
- Recent advancements in Natural Language Understanding and Generation have outshone progress in machine vision.
- Foundation models have been successful in NLP tasks but face challenges in computer vision.
- Stanford researchers propose CWM (Counterfactual World Modeling) as a framework for a visual foundation model.
- CWM comprises structured masking, capturing low-dimensional structure in visual data through minimal visual tokens.
- Counterfactual prompting enables zero-shot computation of various visual representations without explicit supervision.
- CWM shows promising capabilities in generating high-quality outputs for key tasks in image and video analysis.
Main AI News:
The landscape of Natural Language Understanding and Natural Language Generation has experienced remarkable advancements in recent years. Notably, the emergence of ChatGPT, a groundbreaking creation by OpenAI, has dominated headlines since its inception. However, while the realm of Generative Artificial Intelligence has made tremendous strides, the quest to achieve human-like visual scene understanding remains a challenge for current large-scale AI algorithms.
Human beings effortlessly grasp visual scenes, effortlessly recognize objects, comprehend spatial arrangements, predict object movements, and understand the complex interactions between objects. Unfortunately, replicating this level of comprehension in AI systems has proven elusive.
One approach that has demonstrated effectiveness in overcoming these challenges involves leveraging foundation models. A foundation model comprises two critical elements: a pretrained model, typically a sophisticated neural network, trained to excel at a masked token prediction task using a vast real-world dataset, and a versatile task interface capable of translating diverse tasks across multiple domains into input for the pretrained model. While foundation models have been extensively utilized in NLP-related tasks, their successful application in the realm of computer vision faces hurdles posed by masked prediction and the inability to access intermediate computations through a single-vision model interface.
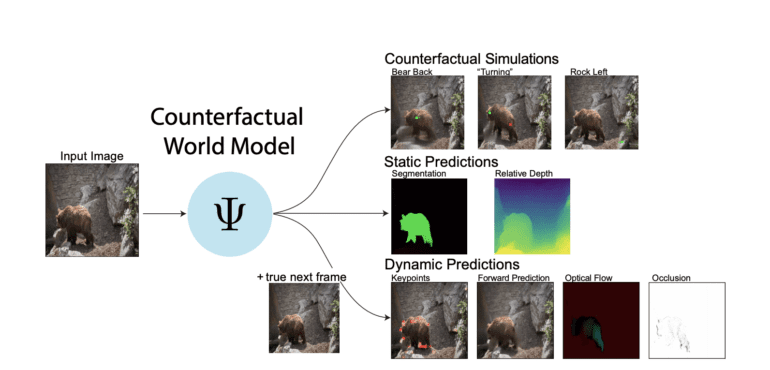
To address these obstacles head-on, a team of dedicated researchers has introduced the Counterfactual World Modeling (CWM) approach, a revolutionary framework designed to construct a visual foundation model. With the primary goal of developing an unsupervised network capable of performing a multitude of visual computations on demand, the team has devised CWM to unify machine vision.
CWM comprises two crucial components that work in tandem to unlock its potential. Firstly, structured masking, an extension of the widely employed masked prediction methods seen in Large Language Models, plays a pivotal role. By leveraging structured masking, the prediction model is incentivized to capture the low-dimensional structure inherent in visual data. Consequently, the model gains the ability to distill a scene’s essential physical elements, showcasing them through a concise collection of visual tokens. This empowers the model to encode critical information about the underlying structure of visual scenes by constructing masks.
The second component of CWM is counterfactual prompting, a groundbreaking technique. By comparing the model’s output on real inputs with slightly modified counterfactual inputs, multiple distinct visual representations can be computed in a zero-shot manner. By perturbing the inputs and examining the resulting changes in the model’s responses, core visual concepts can be derived. The brilliance of this counterfactual approach lies in its ability to extract various visual computations without the need for explicit supervision or task-specific designs.
The authors of this groundbreaking research emphasize that CWM has exhibited remarkable capabilities in generating high-quality outputs for a wide array of tasks involving real-world images and videos. These tasks encompass the estimation of key points, optical flow, occlusions, object segments, and relative depth. From pinpointing specific points crucial for object recognition to analyze the pattern of apparent motion in an image sequence, CWM has showcased its prowess. With its potential to unify the diverse strands of machine vision, CWM stands as a promising approach poised to revolutionize the field.
Conclusion:
The introduction of CWM (Counterfactual World Modeling) as a framework for a visual foundation model marks a significant breakthrough in the field of machine vision. By addressing the challenges faced by current large-scale AI algorithms, CWM has the potential to unify machine vision and bridge the gap between human-like visual scene understanding and AI systems. The application of CWM in generating high-quality outputs for diverse tasks signifies its viability and relevance in real-world scenarios.
As a result, the market can expect advancements in object recognition, optical flow analysis, occlusion understanding, object segmentation, and relative depth estimation. CWM paves the way for more robust and sophisticated machine vision systems, opening up new possibilities for industries ranging from autonomous vehicles and robotics to healthcare and surveillance. Businesses should closely monitor the developments and opportunities arising from the implementation of CWM, as it holds the potential to revolutionize various sectors and provide a competitive edge in the market.