
TL;DR:
- One-2-3-45++ is an innovative AI method revolutionizing 3D object generation.
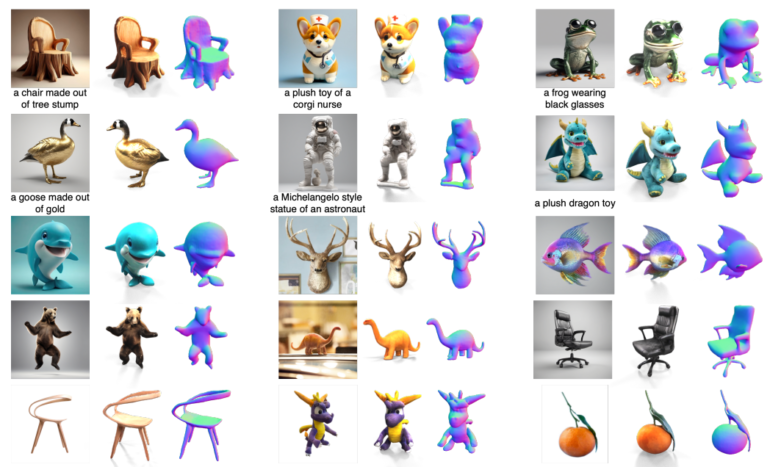
- It converts a single image into a detailed 3D textured mesh in approximately one minute.
- The method leverages 2D diffusion models and multi-view conditioning for superior results.
- It outperforms baseline methods in CLIP similarity and user preference scores.
- One-2-3-45++ addresses the challenge of generating 3D shapes from single images efficiently.
- The technology holds great potential for applications in virtual reality, gaming, and design.
Main AI News:
Cutting-edge technology is transforming the world of 3D object generation, and at the forefront of this revolution stands One-2-3-45++, a groundbreaking AI method developed by researchers from UC San Diego, Zhejiang University, Tsinghua University, UCLA, and Stanford University. In the fast-paced landscape of artificial intelligence, One-2-3-45++ is making waves with its ability to convert a single image into a detailed 3D textured mesh in just about one minute.
The method’s journey begins with the utilization of 2D diffusion models, meticulously fine-tuning them to ensure consistent multi-view image generation. Once this crucial step is complete, multi-view conditioned 3D native diffusion models step in, weaving their magic to transform these images into intricate 3D textured meshes. The result? High-quality, diverse 3D assets that closely mirror the input image, all achieved in approximately one minute. One-2-3-45++ is the answer to the demands for speed and fidelity in practical applications of 3D object generation.
A Revolution in 3D Object Generation
One-2-3-45++ is a game-changer, delivering high-fidelity 3D objects from a single RGB image in less than a minute. Leveraging the power of multi-view images, this method refines the texture of the generated mesh through a lightweight optimization process. Comparative evaluations have unequivocally shown the superiority of One-2-3-45++ over baseline methods when it comes to CLIP similarity and user preference scores. The pivotal role of multi-view images in enhancing the efficacy of the 3D diffusion module cannot be overstated, as it ushers in a new era of consistent multi-view generation.
Addressing Critical Challenges
The research underpinning One-2-3-45++ tackles the formidable challenge of generating 3D shapes from single images or text prompts, a necessity for various applications. Existing methods have struggled to generalize across unseen categories due to a dearth of 3D training data. Enter One-2-3-45++, which transcends the limitations of its predecessor, One-2-3-45, by simultaneously predicting consistent multi-view images and harnessing a multiview conditioned 3D diffusion-based module for efficient and lifelike 3D reconstruction. The results speak for themselves – high-quality outcomes with granular control, all achieved in under a minute, surpassing baseline methods.
The Inner Workings of Excellence
The One-2-3-45++ model, forged through extensive training on multi-view and 3D pairings, relies on separate diffusion networks for each stage of its operation. The first stage employs normal 3D convolution to craft the full 3D occupancy volume, while the second stage incorporates 3D sparse convolution for the 3D light volume. A nimble refinement module, guided by multi-view images, elevates texture quality to new heights. Evaluation metrics, including CLIP similarity and user preference scores, unmistakably establish the method’s superiority over baseline approaches. A user study further underscores its quality, highlighting its runtime efficiency when compared to existing methods.
Unparalleled Quality and Speed
One-2-3-45++ reigns supreme in CLIP similarity and user preference scores, setting a new benchmark for quality and performance. The refinement module, a key player in this success story, enriches texture quality, resulting in higher CLIP similarity scores. Notably, this method offers substantial runtime advantages when juxtaposed with optimization-based alternatives, delivering swift results that meet the demands of today’s fast-paced world.
Conclusion:
One-2-3-45++ is a highly efficient technology that can swiftly produce high-quality 3D textured meshes from a single image with remarkable precision. A comprehensive user study has unequivocally validated its superiority, both in terms of quality and alignment with input images. Moreover, it excels in speed, outpacing optimization-based alternatives. As we gaze into the future, the potential of One-2-3-45++ is limitless. Future research avenues include harnessing larger and more diverse 3D training datasets, exploring advanced post-processing techniques, fine-tuning the texture refinement module, conducting extensive user studies, and integrating diverse information types. The impact of this method in domains such as virtual reality, gaming, and computer-aided design holds immense promise, and further exploration is key to unlocking its full potential.