
TL;DR:
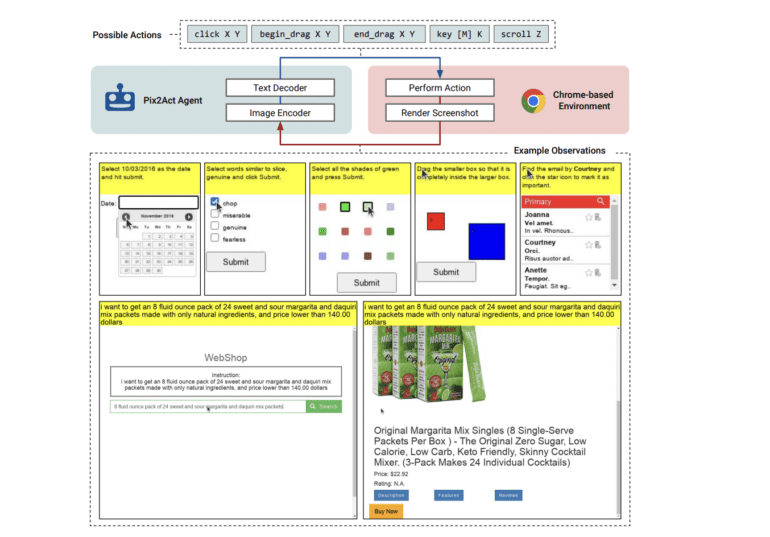
- Pix2Act is an AI agent that enables interaction with GUIs using pixel-based screenshots and generic keyboard and mouse actions.
- GUI-based digital agents often rely on HTML-derived textual representations, but Pix2Act leverages visual input and standard mouse and keyboard shortcuts for intuitive navigation.
- Learning from pixel-only inputs in GUI-based tasks presents challenges in interface interpretation and understanding visual elements and their functions.
- Google DeepMind and Google introduce PIX2ACT, a model that outperforms human crowdworkers by using pixel inputs and generic action space, matching state-of-the-art agents using DOM information.
- PIX2ACT expands upon PIX2STRUCT, a Transformer-based image-to-text model trained on online data, and employs tree search to construct new expert trajectories for training.
- The framework created for universal browser-based environments and the adaptation of benchmark datasets demonstrate PIX2ACT’s superior performance.
- PIX2STRUCT’s pre-training through screenshot parsing enhances the efficacy of GUI-based instruction followed by pixel-based inputs.
- While there is still a performance gap compared to models using HTML-based inputs, PIX2ACT sets a crucial baseline for future advancements.
Main AI News:
In today’s digital age, the ability to connect with tools and services through graphical user interfaces (GUIs) has become increasingly important. Automating laborious tasks, enhancing accessibility, and maximizing the functionality of digital assistants are just a few of the benefits that systems capable of following GUI directions can provide.
While many existing GUI-based digital agents rely on HTML-derived textual representations, such resources are not always readily available. Humans, on the other hand, effortlessly navigate GUIs by simply perceiving visual cues and executing actions using familiar mouse and keyboard shortcuts. They don’t require knowledge of the application’s source code to operate the program effectively. Thanks to intuitive graphical user interfaces, individuals can quickly adapt to new software regardless of the underlying technology.
The Atari game system serves as a remarkable example of the potential of learning from pixel-only inputs. However, combining pixel-only inputs with generic low-level actions to accomplish GUI-based instruction following tasks presents numerous challenges. Successfully interpreting a GUI requires familiarity with its structure, the ability to recognize and interpret visually located natural language, identification of visual elements, and forecasting the functions and interaction methods associated with those elements.
Addressing these obstacles head-on, Google DeepMind and Google have jointly developed PIX2ACT—an innovative model that leverages pixel-based screenshots as input and selects actions based on fundamental mouse and keyboard controls. For the first time, this groundbreaking research showcases that an agent relying solely on pixel inputs and a generic action space can outperform human crowdworkers, achieving performance on par with state-of-the-art agents that utilize DOM information and a similar number of human demonstrations.
Building upon the success of PIX2STRUCT, a Transformer-based image-to-text model previously trained on vast amounts of online data to convert screenshots into structured representations using HTML, the researchers have expanded their work to create PIX2ACT. This novel model employs tree search to construct expert trajectories for training, combining human demonstrations with interactions within the environment.
To ensure the model’s versatility across various browser-based environments, the team has developed a comprehensive framework while adapting two benchmark datasets—MiniWob++ and WebShop—to a standardized, cross-domain observation and action format. By utilizing their proposed option (CC-Net without DOM), PIX2ACT achieves approximately four times better performance than human crowdworkers on MiniWob++. Ablation studies further validate the crucial role of PIX2STRUCT’s pixel-based pre-training in the impressive performance of PIX2ACT.
In the realm of GUI-based instruction following pixel-based inputs, these findings underscore the effectiveness of PIX2STRUCT’s pre-training approach through screenshot parsing. Notably, pre-training within a behavioral cloning environment significantly boosts MiniWob++ and WebShop task scores by 17.1 and 46.7, respectively. While there remains a performance gap compared to larger language models utilizing HTML-based inputs and task-specific actions, this work establishes an essential baseline within this domain.
Pix2Act represents a groundbreaking advancement in AI technology, empowering machines to interact with GUIs using the same conceptual interface humans effortlessly comprehend. By bridging the gap between pixel-based inputs and generic actions, this innovative model sets a new standard for GUI-based instruction following. With further advancements and refinements, Pix2Act holds the potential to revolutionize the way we interact with digital tools and services, unlocking unprecedented efficiency and usability in the process.
Conclusion:
The development of Pix2Act signifies a significant breakthrough in the market. This AI technology allows for seamless interaction with graphical user interfaces, making it easier for users to connect with tools and services. By leveraging pixel-based screenshots and generic keyboard and mouse actions, Pix2Act streamlines laborious tasks, enhances accessibility and boosts the effectiveness of digital assistants. With its impressive performance, Pix2Act sets a new standard in GUI-based instruction following and holds great potential for revolutionizing the way individuals interact with digital interfaces. This advancement opens doors for increased automation, improved user experiences, and enhanced productivity across various industries, making it a valuable asset in the ever-evolving market.