
TL;DR:
- GPT model by OpenAI utilizes in-context learning, which reduces the need for extensive fine-tuning.
- In-context learning faces challenges when applied to graph machine learning tasks.
- PRODIGY is a pretraining framework that enables in-context learning over graphs.
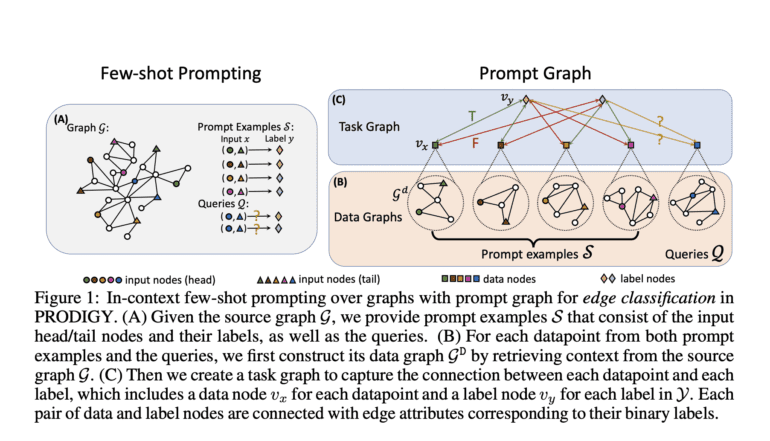
- PRODIGY utilizes prompt graph representation to integrate nodes, edges, and graph-level tasks.
- It offers a specialized graph neural network architecture for the effective processing of prompt graphs.
- PRODIGY outperforms contrastive pretraining baselines and standard fine-tuning in terms of accuracy.
- It shows promise for graph-based scenarios and enables downstream classification on unseen graphs.
Main AI News:
In the realm of artificial intelligence, the GPT model has gained immense popularity as the driving force behind ChatGPT, a renowned chatbot developed by OpenAI. At the core of this transformer architecture lies the concept of learning tasks with minimal examples, known as in-context learning. By leveraging this approach, the model bypasses the need for extensive fine-tuning with thousands of input texts and instead learns to excel across various tasks using task-specific examples as input. Fine-tuning such a large Language model like GPT, with billions of parameters, can be a costly endeavor, making in-context learning a cost-effective alternative.
While in-context learning has proven effective for tasks like code generation, question answering, and machine translation, it encounters challenges when applied to graph machine learning tasks. Graph machine learning encompasses tasks such as identifying spreaders of half-truths or false news on social networks and providing product recommendations on e-commerce platforms. Formulating and modeling these tasks over graphs in a unified representation that enables the model to handle diverse tasks without retraining or parameter tuning remains a significant hurdle for in-context learning.
Recently, a team of researchers introduced PRODIGY, an innovative pretraining framework designed to empower in-context learning over graphs. PRODIGY, short for Pretraining Over Diverse In-Context Graph Systems, formulates in-context learning by leveraging a prompt graph representation. This prompt graph serves as an in-context task representation, seamlessly integrating the modeling of nodes, edges, and graph-level machine learning tasks. The prompt network establishes connections between input nodes or edges and additional label nodes, contextualizing prompt examples and inquiries. This interconnected representation enables the specification of diverse graph machine learning tasks to a single model, regardless of graph size.
Developed by a collaborative team from Stanford University and the University of Ljubljana, PRODIGY introduces a specialized graph neural network architecture tailored to process the prompt graph effectively. This architecture employs graph neural networks (GNNs) to teach representations of the prompt graph’s nodes and edges. Furthermore, a range of in-context pretraining objectives has been introduced to guide the learning process, providing supervision signals that enable the model to capture relevant graph patterns and generalize across diverse tasks.
To evaluate the performance and effectiveness of PRODIGY, the authors conducted experiments on tasks involving citation networks and knowledge graphs. Citation networks represent relationships between scientific papers, while knowledge graphs capture structured information across different domains. The pretrained model underwent rigorous testing using in-context learning, with the results compared against contrastive pretraining baselines featuring hard-coded adaptation and standard fine-tuning with limited data. Notably, PRODIGY surpassed contrastive pretraining baselines with hard-coded adaptation by an average of 18% in terms of accuracy. Furthermore, when in-context learning was applied, PRODIGY achieved an average improvement of 33% over standard fine-tuning with limited data.
Conclusion:
The introduction of PRODIGY and its pretraining framework marks a significant advancement in the field of graph machine learning. By enabling in-context learning over graphs, PRODIGY addresses the limitations faced by traditional methods and paves the way for more efficient and versatile approaches. With its superior performance in accuracy and ability to handle diverse tasks without retraining, PRODIGY is set to revolutionize graph-based scenarios. This development opens up new possibilities and opportunities for businesses operating in areas such as social networks, e-commerce, and knowledge graphs. Embracing PRODIGY can empower organizations to make more informed decisions, enhance recommendation systems, and combat the spread of misinformation, ultimately driving growth and success in the market.