
TL;DR:
- Researchers introduce VISPROG, a neuro-symbolic approach for solving complex visual tasks using natural language instructions.
- VISPROG breaks down difficult activities into simpler phases and leverages big language models and specialized end-to-end trained models.
- It allows users to build complicated programs without prior training, offering flexibility and abstraction.
- VISPROG combines modules such as language models, image processing subroutines, and computer vision models.
- It provides interpretability, enabling users to understand and verify program logic.
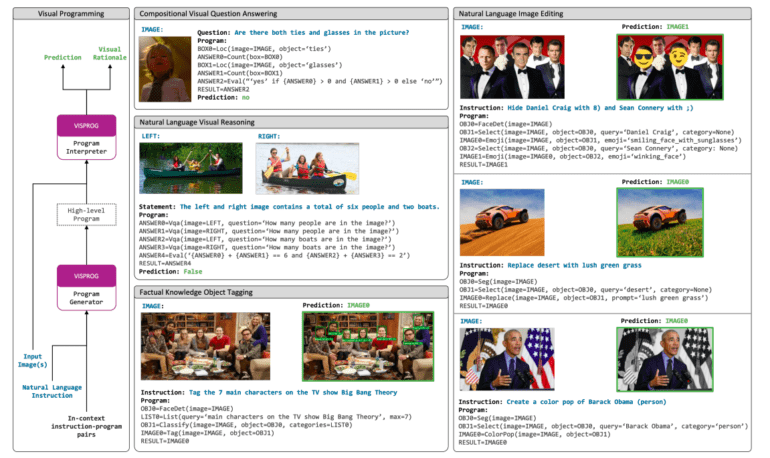
- VISPROG demonstrates versatility in tasks like compositional visual questions, NLVR, knowledge tagging, and image manipulation.
- The system achieves significant performance improvements and sets a new standard in AI systems.
Main AI News:
The pursuit of universal AI systems has paved the way for the advancement of comprehensive end-to-end trainable models, many of which aim to provide users with a user-friendly natural language interface. Achieving this has typically relied on massive-scale unsupervised pretraining followed by supervised multitask training, enabling these systems to handle a wide array of tasks. However, scaling these systems to tackle an indefinite number of complex jobs poses a significant challenge. This necessitates a meticulous selection of datasets tailored to each specific task.
In a groundbreaking study, researchers from the Allen Institute for AI have delved into the utilization of large language models to address the long tail of intricate tasks. They propose a novel approach that involves deconstructing complex activities expressed in natural language into simpler phases, which can be efficiently handled by specialized end-to-end trained models or other programs.
Imagine instructing a computer vision program to “Tag the seven main characters from the TV show Big Bang Theory in this image.” Before carrying out this instruction, the system must first comprehend its purpose, followed by a series of steps: face detection, retrieving the list of Big Bang Theory’s main characters from a knowledge base, face classification using the character list, and finally tagging the image with the recognized characters’ names and faces. While various vision and language systems can perform each individual task, executing natural language instructions remains beyond the capabilities of end-to-end trained systems.
To address this challenge, the researchers introduce VISPROG—an innovative program that takes visual information (a single picture or a collection of images) and a natural language command as input. VISPROG creates a series of instructions, referred to as a visual program, which is then executed to produce the desired outcome. Each line of the visual program calls upon one of the many supported modules within the system. These modules can range from pre-built language models and OpenCV image processing subroutines to arithmetic and logical operators. Moreover, pre-built computer vision models can also be integrated. The outputs generated by running earlier lines of code are consumed by subsequent modules, producing intermediate outputs that can be utilized later in the program.
Returning to the previous example, VISPROG utilizes a face detector, GPT-3 as a knowledge retrieval system, and CLIP as an open-vocabulary image classifier within the visual program to provide the necessary output. This holistic approach enhances both the generation and execution of programs for vision applications. Neural Module Networks (NMN) play a crucial role in this context. These networks combine differentiable neural modules in a question-specific manner to create an end-to-end trainable network for visual question answering (VQA) problems. Existing methods either train a layout generator using weak answer supervision or rely on brittle, pre-built semantic parsers to generate deterministic module layouts. VISPROG, on the other hand, empowers users to construct complex programs without prior training, leveraging the power of the GPT-3 language model and limited in-context examples. By invoking state-of-the-art models, non-neural Python subroutines, and greater levels of abstraction compared to NMNs, VISPROG programs achieve a higher degree of abstraction.
These advantages position VISPROG as a swift, efficient, and versatile neuro-symbolic system. Furthermore, VISPROG emphasizes interpretability. Firstly, it generates programs that are easy to understand, allowing users to verify their logical accuracy. Secondly, by breaking down predictions into manageable parts, VISPROG enables users to scrutinize the results of intermediate phases, identify flaws, and make necessary corrections to the logic.
To visually justify the predictions, a completed program showcases intermediate step outputs such as text, bounding boxes, segmentation masks, and produced pictures, all interconnected to illustrate the flow of information. The researchers demonstrate the versatility of VISPROG by applying it to four distinct activities. These tasks require a combination of fundamental skills like picture parsing and specialized cognitive abilities related to visual manipulation and critical thinking. The tasks include answering compositional visual questions, conducting zero-shot NLVR (Natural Language for Visual Reasoning) on picture pairings, object labeling based on factual knowledge from NL (Natural Language) instructions, and language-guided image manipulation.
Importantly, the researchers highlight that none of the modules or the language model itself has been modified in any way. By providing a few in-context examples with natural language commands and appropriate programs, VISPROG can be adapted to any given task effortlessly. Its user-friendly nature and significant performance improvements, including a 2.7-point enhancement on the compositional VQA test, robust zero-shot accuracy of 62.4% on NLVR, and impressive qualitative and quantitative results in knowledge tagging and picture editing tasks, solidify VISPROG as a groundbreaking neuro-symbolic system.
Conclusion:
The introduction of VISPROG represents a significant advancement in the market for AI systems. By combining a neuro-symbolic approach with natural language instructions, VISPROG enables the development of sophisticated visual programs for complex tasks. Its flexibility, interpretability, and performance improvements make it an attractive solution for businesses and industries seeking efficient and versatile AI systems. VISPROG sets a new standard in human-machine interactions, paving the way for more intuitive and productive applications across various sectors.