
- Large Language Models (LLMs) pose computational challenges due to their extensive size.
- Parameter-Efficient Fine-Tuning (PEFT) selectively adjusts model parameters for specific tasks.
- PEFT methods include additive, selective, reparameterized, and hybrid fine-tuning techniques.
- Researchers assess PEFT algorithms’ performance, computational demands, and real-world implementation costs.
- Analysis of computation costs and memory overhead in LLMs provides insights for optimization.
- Understanding efficient fine-tuning strategies is crucial for businesses leveraging LLMs in diverse applications.
Main AI News:
Large Language Models (LLMs) have revolutionized various sectors with their remarkable capabilities, yet their extensive size poses significant computational challenges. With billions of parameters, these models require substantial computational resources, especially on hardware with limited capabilities.
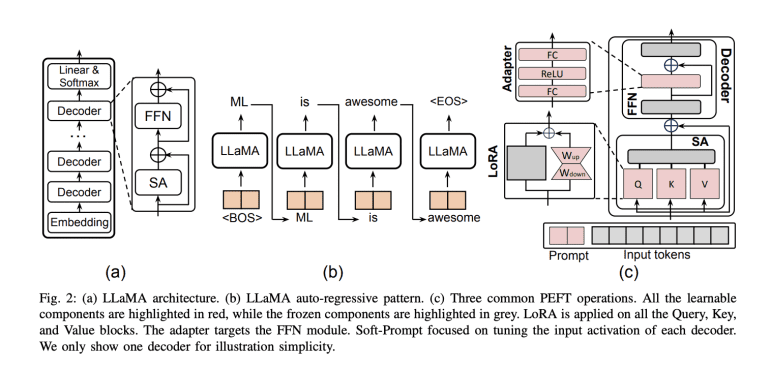
While LLMs demonstrate impressive generalization abilities, fine-tuning remains essential for optimizing performance on specific tasks. Parameter-Efficient Fine-Tuning (PEFT) is a widely adopted strategy, selectively adjusting a subset of parameters while keeping the majority untouched. This approach is vital for tasks across Natural Language Processing (NLP) and computer vision (CV), including Vision Transformers (ViT) and interdisciplinary vision-language models.
A recent survey by researchers from esteemed institutions meticulously explores diverse PEFT algorithms, assessing their performance and computational demands. It also examines applications developed using these methods and strategies to mitigate computational expenses. Moreover, the survey investigates real-world system designs to understand the implementation costs associated with PEFT.
PEFT algorithms are categorized into additive, selective, reparameterized, and hybrid fine-tuning. Additive fine-tuning includes techniques like adapters and soft prompts, which introduce additional tunable modules or parameters. Selective fine-tuning focuses on modifying a small subset of parameters, categorized into Unstructural Masking and Structural Masking. Reparametrization involves transforming model parameters, utilizing strategies like Low-rank Decomposition and LoRA Derivatives. Hybrid fine-tuning combines different PEFT methods for optimal results.
To analyze computation costs and memory overhead, researchers established parameters in LLMs. These models generate tokens iteratively based on input prompts and previously generated sequences, optimizing inference by storing previous Keys and Values in a KeyValue cache (KV-cache).
As businesses increasingly rely on LLMs for diverse applications, understanding and implementing efficient fine-tuning strategies become paramount. This survey provides invaluable insights into PEFT algorithms, enabling researchers to navigate the complexities of large-scale language model optimization effectively.
Conclusion:
Effective fine-tuning strategies for Large Language Models (LLMs) are paramount as businesses leverage these models for diverse applications. Understanding the nuances of Parameter-Efficient Fine-Tuning (PEFT) algorithms and their implementation costs is essential for optimizing LLM performance and driving innovation in the market.