
- Iterative refinement methods show promise in boosting language model performance, particularly in reasoning tasks.
- Offline techniques like Dynamic Programming with Optimization (DPO) gain popularity for their simplicity and effectiveness.
- Recent advancements introduce iterative approaches such as Iterative DPO, Self-Rewarding LLMs, and SPIN, aiming to enhance model performance through preference optimization.
- Researchers propose an iterative preference optimization method tailored for Chain-of-Thought (CoT) reasoning tasks, yielding significant improvements in reasoning prowess.
- Experimental results demonstrate substantial performance enhancements across various datasets, surpassing models that do not leverage additional datasets.
Main AI News:
In the realm of language model optimization, iterative refinement methodologies stand out for their potential to elevate performance, particularly in reasoning tasks. While traditional fine-tuning approaches offer limited enhancements, iterative preference optimization methods present a promising avenue for aligning models more closely with human requirements. Notably, offline techniques like Dynamic Programming with Optimization (DPO) are gaining traction owing to their simplicity and effectiveness.
Recent strides in this domain advocate for the iterative application of offline procedures, introducing concepts like Iterative DPO, Self-Rewarding Language Models (LLMs), and SPIN. These methodologies aim to construct new preference relations iteratively, thereby augmenting model performance. Despite the success of iterative training methods such as STaR and RestEM in reasoning tasks, the potential of preference optimization remains largely untapped.
Iterative alignment strategies encompass both human-in-the-loop and automated approaches. While some methods rely on human feedback, such as Reinforcement Learning with Human Feedback (RLHF), others like Iterative DPO autonomously optimize preference pairs. SPIN, a variant of Iterative DPO, leverages both human labels and model-generated preferences. However, challenges arise when model performance aligns closely with human standards.
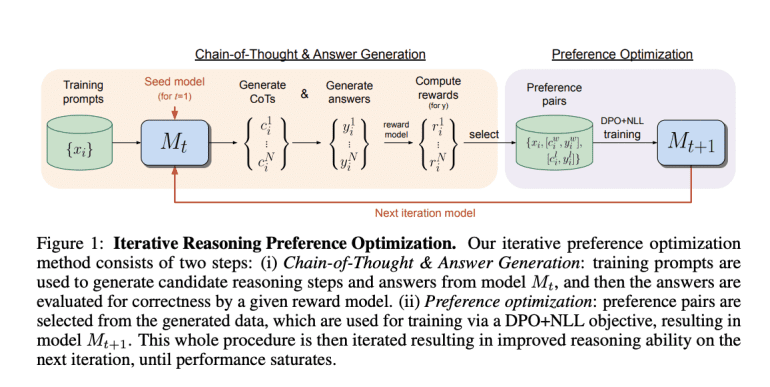
A notable contender in this arena is the approach proposed by researchers from FAIR at Meta and New York University. Their method targets iterative preference optimization specifically for Chain-of-Thought (CoT) reasoning tasks. Each iteration involves sampling multiple CoT reasoning steps and final answers, constructing preference pairs based on correctness. Training incorporates a DPO variant with a negative log-likelihood (NLL) loss term, crucial for performance enhancement.
This iterative process iterates by generating new pairs and retraining the model, refining its performance incrementally. Central to this approach is a base language model, typically pre-trained or instruction-tuned, and a dataset of training inputs. The model generates a sequence of reasoning steps and a final answer for each input. While final answer correctness is evaluated, reasoning step accuracy is not explicitly considered.
Experimental results demonstrate the efficacy of this approach, showcasing significant improvements in reasoning prowess over successive iterations. For instance, performance metrics for the Llama-2-70B-Chat model witness substantial escalation across various datasets. Notably, accuracy surges from 55.6% to 81.6% on GSM8K, from 12.5% to 20.8% on MATH, and from 77.8% to 86.7% on ARC-Challenge. These improvements outshine those achieved by Llama-2-based models that do not leverage additional datasets.
Conclusion:
The development and successful application of iterative refinement techniques for language models, particularly in reasoning tasks, indicate a growing sophistication in AI capabilities. This not only opens doors for improved natural language understanding but also presents lucrative opportunities for businesses operating in AI-driven industries such as customer service, content generation, and data analysis. By harnessing these advancements, companies can gain a competitive edge by deploying more intelligent and context-aware language models, ultimately enhancing user experience and operational efficiency.