
TL;DR:
- Large language models (LLMs) have gained attention for their versatility in open-ended tasks.
- Current benchmarks and metrics fail to adequately assess LLMs in open-ended scenarios.
- JudgeLM, a novel approach, utilizes optimized open-source LLMs as scalable judges for evaluation.
- A high-quality dataset, comprising 105K seed questions and judgments, is central to JudgeLM’s methodology.
- Biases in LLM judgments, such as position, knowledge, and format biases, are addressed.
- JudgeLM offers expanded features, including multi-turn conversations and multimodal models.
- It provides a cost-effective and privacy-conscious solution for LLM evaluation.
- The dataset presented is the most comprehensive, promising to advance future model analysis.
Main AI News:
In the realm of large language models (LLMs), a revolutionary approach has emerged, captivating the attention of the tech world. These LLMs, celebrated for their remarkable aptitude in adhering to instructions and navigating a myriad of open-ended scenarios, have sparked a new era of possibilities. Leveraging instruction fine-tuning, researchers have devised a plethora of techniques aimed at aligning these models with human preferences, drawing inspiration from open-source LLMs like FlanT5, OPT, LLaMA, and Pythia. The result? Aligned LLMs exhibit a heightened understanding of human commands and deliver responses of unparalleled logic.
Yet, in this ever-evolving landscape, a pressing question arises: Are the capabilities of LLMs in open-ended scenarios adequately measured by existing benchmarks and traditional metrics? The answer, it seems, is a resounding “no.”
Consequently, the need for a groundbreaking benchmarking approach that can comprehensively evaluate LLMs in open-ended activities has emerged. In parallel, researchers are diligently exploring diverse methodologies to gauge LLM performance. Some adopt arena-format techniques, harnessing the power of crowdsourcing platforms to obtain anonymized LLM competition results. While human evaluations are deemed reliable, they come at a price, both in terms of monetary cost and effort expended. Others have turned to GPT-4 as an adjudicator, yet these approaches grapple with variable API model shifts and potential data exposure, posing a threat to the repeatability of judgments.
Enter PandaLM, a commendable effort to enhance open-source LLMs used for answer evaluation. However, despite its noble intentions, the efficacy of such refined models in a judicial context is hampered by limitations stemming from model size, data quality, and inherent LLM biases.
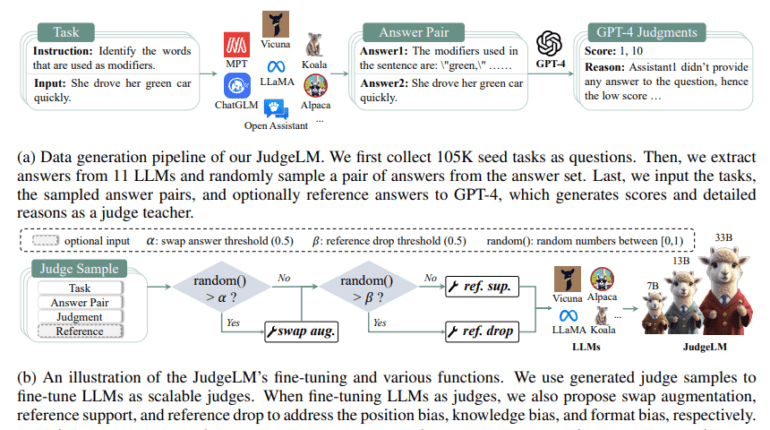
In a recent study, researchers from the Beijing Academy of Artificial Intelligence and Huazhong University of Science & Technology propose a novel paradigm for evaluating LLMs – a paradigm that employs optimized open-source LLMs as scalable judges, aptly named “JudgeLM.” This innovative approach seeks to attain a satisfactory level of agreement with the instructor judge. The technique hinges on a high-quality dataset tailored for training and evaluating judge models, with scalable judges taking on the role of evaluators in open-ended assignments. Open-source LLMs are meticulously adapted to serve as judges within this framework, with a meticulous examination of their scaling capabilities concerning model size (ranging from 7B to 33B) and training data volume (spanning from 3.5K to 100K).
The curated dataset at the core of their study comprises a staggering 105K seed questions, LLM answer pairs, and assessments by the teacher judge, GPT-4. It’s noteworthy that for each seed challenge, students provide two decisions – one with reference answers and another without. This dataset is thoughtfully partitioned, with 100K seed questions earmarked for training (twice the size of PandaLM) and the remainder reserved for validation (a staggering 29 times larger than PandaLM). The inevitable introduction of biases – including position bias favoring specific responses, knowledge bias relying heavily on pre-trained information, and format bias optimizing performance under specific prompt forms – is addressed with meticulous strategies.
Furthermore, as depicted in Figure 1b, the JudgeLM system boasts an array of expanded features, including multi-turn conversations, single-reply grading, and multi-answer assessments, all in addition to multimodal models. When compared to arena-format approaches, JudgeLM stands out as a swift and cost-effective solution. Take, for instance, JudgeLM-7B, a model capable of assessing 5000 response pairs in just 3 minutes, powered by a mere 8 A100 GPUs. Notably, JudgeLM offers enhanced privacy protection and repeatability when compared to closed-source LLM judges. Their method delves deep into the scaling capabilities and biases associated with LLM fine-tuning, setting it apart from concurrent open-source LLM judges.
Conclusion:
The emergence of JudgeLM signifies a significant advancement in LLM evaluation. With its innovative approach, it addresses the limitations of existing methods, offering improved scalability, privacy, and reliability. This development is poised to reshape the market by providing businesses with a more robust means of assessing and fine-tuning language models, ultimately enhancing their performance in open-ended scenarios and customer interactions.