
- Researchers propose LayerSkip, a novel approach to accelerate large language models (LLMs) by reducing layer count per token through early inference exit.
- Unlike traditional methods like quantization or sparsity, LayerSkip doesn’t require specific hardware or software kernels.
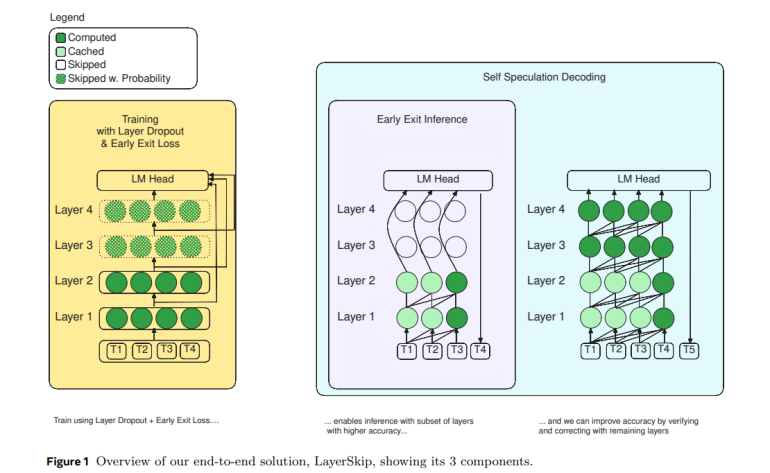
- Self-speculative decoding merges early departure with speculative decoding, eliminating the need for extra models or auxiliary layers.
- Experiments with a Llama1 7B model demonstrate the efficacy of LayerSkip in streamlining inference processes.
- Integration of layer dropout and early exit loss enhances model efficiency and accuracy.
- Adoption of LayerSkip could pave the way for parameter-efficient strategies, improving overall model performance.
Main AI News:
Large language models (LLMs) have become integral to numerous applications, but their deployment on GPU servers often comes with a hefty price tag in terms of energy consumption and financial resources. While some acceleration methods exist for commodity GPUs in laptops, their precision leaves room for improvement. The focus has often been on reducing non-zero weights, but sparsity, defined as the ratio of bits to weight, remains a challenge.
However, a consortium of researchers from FAIR, GenAI, Reality Labs at Meta, University of Toronto, Carnegie Mellon University, University of Wisconsin-Madison, and Dana-Farber Cancer Institute have embarked on a groundbreaking exploration: reducing layer count per token through early inference exit. Unlike quantization or sparsity methods, this approach doesn’t necessitate specific hardware or software kernels.
In the realm of LLM acceleration, speculative decoding has emerged as a prominent trend. Traditionally, it involves pairing a massive model (the main model) with a swifter counterpart (the draft model), without compromising accuracy. Yet, managing the key-value (KV) cache in two separate models entails significant effort. Enter self-speculative decoding – a novel approach that merges early departure with speculative decoding, eliminating the need for extra models or auxiliary layers.
By analyzing an example prompt, the researchers unravel the intricacies of each tier within an LLM, bolstering their methodology. They conduct experiments with a Llama1 7B model, trained on the HumanEval coding dataset, showcasing how each token is generated and projected onto the language model (LM) head. They underscore the significance of layer dropout, ensuring the model isn’t overly reliant on subsequent layers.
But the journey doesn’t end there. The team delves deeper, integrating a loss function into the training process to enhance the LM heads’ comprehension of preceding layer embeddings. Their approach streamlines deployment and maintenance, slashes training times, and curtails memory consumption during both inference and training phases.
Looking ahead, the researchers advocate for the adoption of layer dropout and early exit loss in pretraining and fine-tuning protocols. This, they believe, could pave the way for parameter-efficient strategies, fostering model performance enhancements. Their vision extends to dynamic conditions for identifying unique exit layers for each token, thereby augmenting the token acceptance rate in self-speculative decoding.
Conclusion:
LayerSkip represents a significant leap forward in the optimization of large language models. Its ability to expedite inference processes while maintaining or even improving accuracy holds immense promise for various industries reliant on AI technologies. Companies investing in AI solutions should closely monitor developments in LayerSkip and consider its integration into their workflows to stay competitive in the market.