
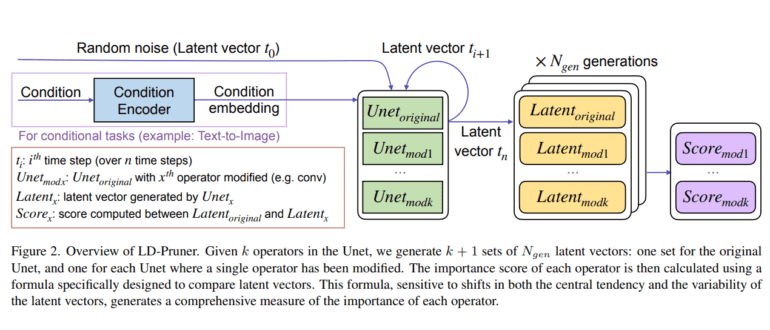
- Researchers introduce LD-Pruner, a novel pruning method for compressing Latent Diffusion Models (LDMs).
- LDMs are powerful generative models used in computer vision and natural language processing.
- LD-Pruner operates in the latent space, ensuring task-agnostic compression without sacrificing performance.
- The method identifies and removes non-contributory components, resulting in faster inference speeds and fewer parameters.
- Experimental results across various tasks validate LD-Pruner’s effectiveness and versatility.
- The proposed approach enhances the interpretability of the pruning process and enables precise model compression.
- LD-Pruner demonstrates practical applicability across text-to-image generation, unconditional image, and audio generation tasks.
Main AI News:
In the realm of generative models, Latent Diffusion Models (LDMs) have emerged as powerful tools, revolutionizing fields like computer vision and natural language processing. Their ability to learn data distributions and generate high-quality samples quickly has made them a focal point of research. However, deploying LDMs on resource-constrained devices poses significant challenges due to their computational demands, especially from components like Unet.
To address this challenge, researchers have explored various compression techniques for LDMs, aiming to reduce computational overhead while preserving performance. Among these techniques, pruning has shown promise. Traditionally used for compressing convolutional networks, pruning has been adapted to LDMs through methods like Diff-Pruning, which identifies non-contributory diffusion steps and important weights to reduce complexity.
Despite its potential, pruning still faces challenges in adaptability and effectiveness across different tasks. Additionally, evaluating its impact on generative models is complex due to resource-intensive metrics like Frechet Inception Distance (FID). In response, Nota AI researchers propose a novel metric for measuring the importance of individual operators in LDMs, leveraging the latent space during pruning.
Their approach operates independently of output types, enhancing computational efficiency by working in the compact latent space. This ensures seamless adaptation to various tasks without task-specific adjustments. By effectively identifying and removing components with minimal contribution to the output, their method produces compressed models with faster inference speeds and fewer parameters.
The study introduces a comprehensive metric for comparing LDM latent representations and formulates a task-agnostic algorithm for compressing LDMs through architectural pruning. Experimental results across various tasks demonstrate the versatility and effectiveness of the proposed approach, promising wider applicability of LDMs in resource-constrained environments.
Moreover, the proposed approach offers a nuanced understanding of LDM latent representations through rigorous experimental evaluations and logical reasoning. By thoroughly assessing each element of the metric’s design, the researchers ensure its effectiveness in accurately comparing LDM latent representations. This level of granularity enhances the interpretability of the pruning process and enables precise identification of components for removal while preserving output quality.
In addition to its technical contributions, the study showcases the practical applicability of the proposed method across three distinct tasks: text-to-image (T2I) generation, Unconditional Image Generation (UIG), and Unconditional Audio Generation (UAG). The successful execution of these experiments underscores the approach’s versatility and potential impact in diverse real-world scenarios. The research validates the proposed method by demonstrating its effectiveness across multiple tasks, paving the way for its adoption in various applications and advancing the field of generative modeling and compression techniques.
Conclusion:
The introduction of LD-Pruner signifies a significant advancement in the compression of Latent Diffusion Models (LDMs), addressing the challenge of deploying these powerful generative models on resource-constrained devices. LD-Pruner’s task-agnostic approach, operating in the latent space, promises not only improved computational efficiency but also enhanced interpretability of model compression. This innovation opens avenues for wider adoption of LDMs across diverse real-world applications, driving further advancements in generative modeling and compression techniques in the market.