
TL;DR:
- Large Language Models (LLMs) have shown remarkable performance in natural language understanding and now, with LENS, they can excel in vision tasks.
- LENS introduces a modular approach, utilizing LLMs as the “reasoning module” and separate “vision modules” to bridge the gap between language and vision.
- Pretrained vision modules extract rich textual information from visual inputs, empowering LLMs to perform tasks like object recognition and vision-language processing.
- LENS eliminates the need for additional multimodal pretraining stages or extensive datasets, making it cost-effective and efficient.
- The integration of LENS enables immediate utilization of advancements in computer vision and natural language processing, maximizing the benefits of both fields.
- LENS achieves competitive zero-shot performance without the need for end-to-end jointly pre-trained models like Kosmos and Flamingo.
Main AI News:
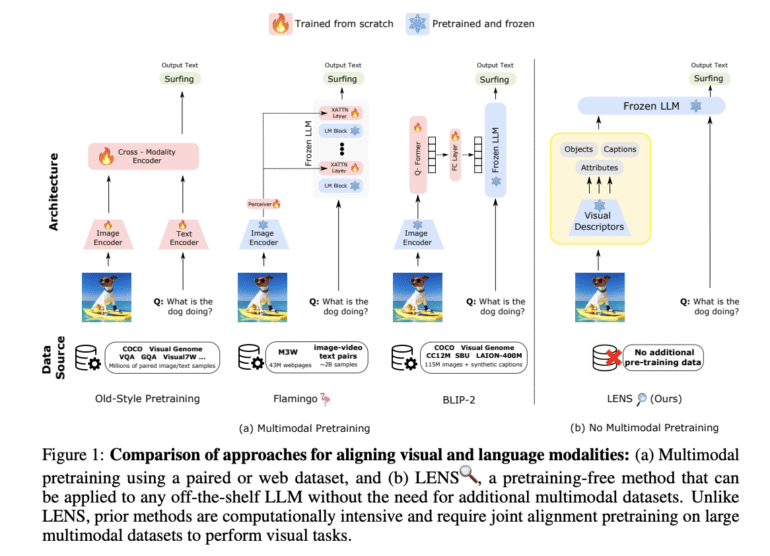
The advancement of Large Language Models (LLMs) has revolutionized natural language understanding, offering impressive capabilities in semantic comprehension, query resolution, and text production. In recent years, LLMs have demonstrated remarkable performance in zero-shot and few-shot environments, especially when it comes to tasks involving vision. Fig. 1(a) illustrates various methods that have been proposed to leverage LLMs in vision-related tasks.
One approach involves training an optical encoder to represent images as continuous embeddings, enabling LLMs to comprehend visual information. Another technique incorporates a contrastively trained frozen vision encoder, augmenting the frozen LLM with additional trainable layers. These added layers are then learned from scratch, enhancing the LLM’s understanding of visual inputs. A lightweight transformer has also been recommended for training, aligning a frozen visual encoder with a frozen LLM. While these methods have made notable progress, the computational cost of the additional pretraining stage(s) remains a challenge. Furthermore, synchronizing visual and linguistic modalities with existing LLMs necessitates vast databases of text, photos, and videos. This is where Flamingo comes into the picture, introducing new cross-attention layers into a pre-trained LLM to incorporate visual features.
However, Flamingo’s multimodal pretraining stage demands an astonishing 2 billion picture-text pairs and 43 million websites, taking up to 15 days to complete. Despite employing a pre-trained image encoder and a frozen LLM, the process is resource-intensive. To circumvent the need for additional multimodal pretraining, Contextual AI and Stanford University researchers present LENS (Large Language Models ENhanced to See). LENS adopts a modular approach, utilizing an LLM as the “reasoning module” and working alongside separate “vision modules.”
The LENS technique begins by extracting detailed textual information from visual inputs using pre-trained vision modules, including contrastive models and image-captioning models. This rich textual information is then fed to the LLM, empowering it to perform various tasks such as object recognition, vision, and language (V&L). Remarkably, LENS seamlessly bridges the gap between modalities without incurring extra costs associated with multimodal pretraining stages or additional data. By incorporating LENS, researchers gain a versatile model capable of operating across domains out of the box, eliminating the need for cross-domain pretraining. Moreover, this integration enables the utilization of cutting-edge advancements in computer vision and natural language processing, maximizing the benefits of both disciplines.
The contributions of this breakthrough are as follows:
- LENS: Contextual AI presents LENS, a modular method that addresses computer vision challenges by leveraging the few-shot, in-context learning capabilities of language models through natural language descriptions of visual inputs. This innovative approach empowers any off-the-shelf LLM with the ability to “see” without the requirement for additional training or data.
- Frozen LLMs: LENS harnesses the power of frozen LLMs to handle object recognition and visual reasoning tasks without the need for vision-and-language alignment or multimodal data. Through extensive experimentation, the research team demonstrates that their approach achieves competitive or even superior zero-shot performance compared to end-to-end jointly pre-trained models like Kosmos and Flamingo.
To explore their groundbreaking work further, a partial implementation of the research paper is available on GitHub. Contextual AI’s LENS propels vision-augmented language models into a new era, unlocking their potential for business applications and beyond.
Conclusion:
The introduction of LENS by Contextual AI represents a significant advancement in the market for vision-augmented language models. This modular approach empowers off-the-shelf LLMs with the ability to comprehend visual inputs, eliminating the need for costly multimodal pretraining. With LENS, businesses can leverage the power of language models to seamlessly integrate vision tasks, opening up new possibilities in domains such as object recognition, vision-language processing, and more. This breakthrough has the potential to drive innovation and enhance productivity in industries that heavily rely on natural language understanding and computer vision technologies.