
TL;DR:
- Large language models (LLMs) like ChatGPT have become essential tools in our daily lives.
- LLMs excel in reasoning tasks, but complex reasoning poses challenges.
- A proposed method employs uncertainty metrics to rank and annotate uncertain questions.
- Four approaches, including disagreement and entropy, estimate uncertainty.
- The solution outperforms baseline methods, enhancing LLM performance on reasoning tasks.
- Active prompting minimizes human efforts by leveraging uncertainty in question annotation.
- In-context learning guides LLMs by providing example question-answer chains.
- CoT prompting endows LLMs with reasoning abilities, but question selection is crucial.
- Active Prompting addresses question prioritization, improving LLMs’ performance.
Main AI News:
In recent months, large language models (LLMs) have become an integral tool in our daily lives, with ChatGPT being at the forefront of this revolution. These models have proven their worth in various applications, such as information retrieval, chat assistance, and writing support. One remarkable aspect of LLMs is their remarkable reasoning capabilities, enabling them to employ logical deduction and inference to solve problems based on available information. They possess the ability to make inferences, draw conclusions, and establish logical connections between different pieces of information. For instance, they can effortlessly answer questions like, “Given the series of numbers: 2, 4, 6, 8, 10, … What is the next number in the sequence?“
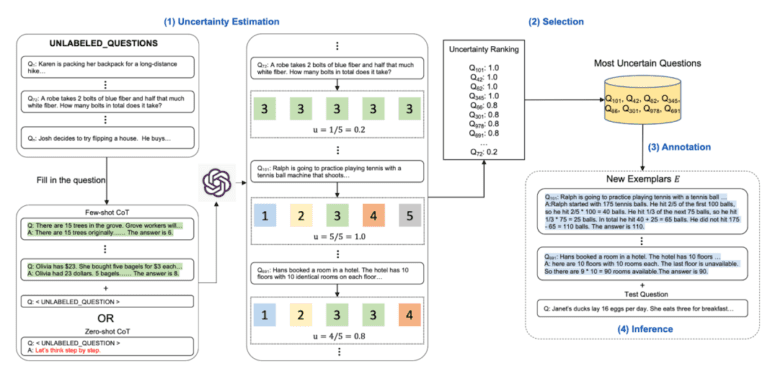
While LLMs excel in tasks that require language understanding, complex reasoning tasks present a new set of challenges. Such tasks demand a higher level of comprehension and reasoning ability, pushing LLMs to their limits. To address this, a proposed method has emerged, introducing several metrics aimed at characterizing the uncertainty within LLM predictions. These uncertainty metrics play a crucial role in ranking the most uncertain questions, which are then selected for annotation. Using a few-shot CoT or zero-shot CoT approach, example answers are generated to aid in the reasoning process.
To estimate uncertainty, four distinct approaches are employed: disagreement, entropy, variance, and self-confidence. Each strategy offers a unique perspective on the nature of uncertainty, but particular emphasis is placed on leveraging disagreement and entropy. Disagreement is determined by calculating the unique answers within the predictions, while higher entropy values signify greater uncertainty, and lower entropy values indicate the opposite. Consequently, when confronted with intricate reasoning tasks, questions with relatively high entropy are more likely to be considered potential options.
The proposed solution undergoes rigorous evaluation across various reasoning tasks, and the results demonstrate its superiority over baseline methods in terms of accuracy and efficiency. Additionally, the paper provides an in-depth analysis of the uncertainty metrics, showcasing how they can enhance model performance.
To summarize, active prompting emerges as a viable solution for determining the most important and beneficial questions for annotation in CoT prompting. By leveraging uncertainty, this approach minimizes the human effort required to annotate a set of questions. The results highlight the effectiveness of the proposed solution in outperforming baseline methods and improving the performance of LLMs in reasoning tasks.
In the realm of guiding LLMs, one straightforward technique is in-context learning. Prior to posing the main request, LLMs are presented with a series of example question-answer pairs, enabling them to grasp the true intent behind the inquiry. For instance, the prompt can be modified from “Given the series of numbers: 2, 4, 6, 8, 10, … What is the next number in the sequence?” to “Q: Given the series of numbers: 2, 4, 6, 8, 10, … What is the next number in the sequence? A: The next number is 12 because each subsequent number increases by two. Q: Given the series of numbers: 3, 7, 11, … What is the next number in the sequence?” This approach allows LLMs to grasp the chain of thought (CoT) and adapt accordingly.
CoT prompting has demonstrated its ability to equip LLMs with robust reasoning capabilities. However, the selection of informative questions and their annotation with CoT and answers heavily relies on human engineering. Undoubtedly, the question-answer chain provided carries the utmost significance.
Given the substantial diversity in difficulty, scope, and domain among reasoning tasks, it remains uncertain which types of questions should receive prioritization for annotation. Moreover, determining whether a specific group of examples is most effective in obtaining the desired information remains unclear. On the other hand, if we could identify the crucial questions, annotating them would become a relatively straightforward task. The question then arises: how do we choose the questions?
This is precisely where Active Prompting comes into play. By leveraging uncertainty and incorporating limited human effort for annotating a small set of questions, this approach proposes a solution to the aforementioned challenge. With Active Prompting, the path to effective question selection becomes clearer, enabling LLMs to excel in reasoning tasks.
Conclusion:
Leveraging active prompting and uncertainty metrics to guide large language models (LLMs) has significant implications for the market. By enhancing LLMs’ reasoning abilities, businesses can benefit from improved accuracy and efficiency in various applications such as information retrieval, chat assistance, and writing support. The ability to tackle complex reasoning tasks effectively can lead to increased productivity and better decision-making processes. With active prompting and the incorporation of uncertainty metrics, LLMs can provide more reliable and insightful solutions, ultimately driving innovation and competitiveness in the market.