
TL;DR:
- LIBERO is a groundbreaking lifelong learning benchmark for robot manipulation.
- It focuses on knowledge transfer in both declarative and procedural domains.
- This benchmark introduces a procedural task generation pipeline with 130 tasks.
- Sequential fine-tuning is shown to be superior for forward transfer in decision-making.
- Visual encoder architecture performance varies, impacting knowledge transfer.
- Naive supervised pre-training can hinder agents in lifelong learning.
- Collaborative efforts from UT Austin, Sony AI, and Tsinghua University drive LIBERO’s development.
- Three vision-language policy networks are employed: RESNET-RNN, RESNET-T, and VIT-T.
- Policy training for tasks is achieved through behavioral cloning.
- RESNET-T and VIT-T outperform RESNET-RNN in decision-making tasks.
- The effectiveness of transformers for temporal data processing is highlighted.
- Sequential fine-tuning is crucial, and careful pre-training is necessary for success.
- LIBERO offers insights for improving neural architecture, algorithms, and pre-training.
- Ensuring long-term user privacy in lifelong learning is emphasized.
Main AI News:
In a groundbreaking development, a consortium of researchers from the University of Texas at Austin, Sony AI, and Tsinghua University has unveiled LIBERO, a transformative benchmark poised to reshape the landscape of lifelong robot learning. This innovative benchmark, designed to investigate knowledge transfer in decision-making processes at scale, marks a significant stride in the realm of robotics.
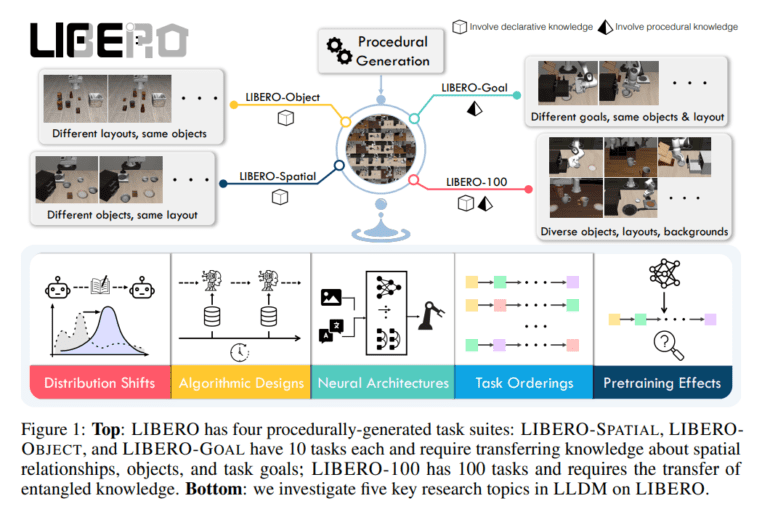
LIBERO, standing for Lifelong Robot Learning Benchmark, is strategically crafted to shed light on five critical research areas within the domain of lifelong learning for decision-making (LLDM). By focusing on both declarative and procedural domains, this benchmark ushers in a new era of possibilities for robot manipulation.
This visionary benchmark introduces a procedural task generation pipeline that comprises a whopping 130 tasks, setting the stage for comprehensive experimentation. LIBERO’s breakthrough lies in its preference for sequential fine-tuning over existing LLDM techniques for forward transfer, revealing an unprecedented level of efficiency.
However, the benchmark also uncovers intriguing variations in the performance of visual encoder architectures. Notably, naive supervised pre-training is identified as a potential roadblock for agents immersed in LLDM tasks. To ensure the highest standards of performance, LIBERO incorporates high-quality human-teleoperated demonstration data for all tasks, offering a well-rounded research environment.
The heart of LIBERO’s success resides in the collaborative efforts of experts in the field. With UT Austin, Sony AI, and Tsinghua University joining forces, the benchmark’s focus extends to the development of a versatile lifelong learning agent. This agent is designed to excel across a wide spectrum of tasks, thereby bridging the gap between theory and practice.
In the realm of vision-language policy networks, LIBERO employs three distinct networks – RESNET-RNN, RESNET-T, and VIT-T. These networks synergize visual, temporal, and linguistic data to process task instructions with precision. Language instructions are meticulously encoded using pre-trained BERT embeddings. RESNET-RNN employs a combination of ResNet and LSTM for visual and material processing, while RESNET-T integrates ResNet with a transformer decoder for visible and temporal token sequences. VIT-T harnesses the power of a Vision Transformer for visual data and combines it with a transformer decoder for temporal data. The policy training for individual tasks is accomplished through behavioral cloning, enabling efficient policy learning even with limited computational resources.
A crucial aspect of LIBERO’s research involves the comparison of neural architectures for lifelong learning in decision-making tasks. RESNET-T and VIT-T emerge as the frontrunners, outperforming RESNET-RNN. This outcome underscores the prowess of transformers in temporal data processing. Furthermore, the performance of these architectures is closely linked to the chosen lifelong learning algorithm, with PACKNET showing no significant difference between RESNET-T and VIT-T, except on the challenging LIBERO-LONG task suite, where VIT-T exhibits exceptional performance. However, in the case of ER, RESNET-T surpasses VIT-T on all task suites except LIBERO-OBJECT, emphasizing the versatility of ViT in processing diverse visual information. Sequential fine-tuning is proven to be the superior approach for forward transfer, while naive supervised pre-training is identified as a potential hindrance, underscoring the strategic importance of pre-training.
Conclusion:
LIBERO stands as a monumental achievement in lifelong robot learning, promising invaluable insights and breakthroughs. It reaffirms the significance of sequential fine-tuning and the critical role of visual encoder architecture in knowledge transfer while highlighting the limitations of naive supervised pre-training. The research points toward exciting future avenues in neural architecture design, algorithmic enhancements for forward transfer, and the strategic utilization of pre-training. Additionally, it emphasizes the utmost importance of safeguarding long-term user privacy in the context of lifelong learning from human interactions.