
- Llama-3-8B-Instruct-80K-QLoRA is a cutting-edge AI model developed for natural language processing (NLP).
- It extends contextual understanding from 8K to 80K tokens, addressing challenges in handling lengthy text passages.
- Leveraging GPT-4 and innovative training techniques, it excels in tasks like QA and summarization.
- Incorporation of RedPajama, LongAlpaca, and synthetic data enhances its contextual grasp.
- Achieves remarkable accuracy in various benchmarks, showcasing superior performance in long-context tasks.
Main AI News:
Artificial intelligence (AI) research continually pushes the boundaries of natural language processing (NLP), aiming to enhance computers’ understanding and generation of human language for more intuitive interactions. Recent strides in this domain have revolutionized machine translation, chatbots, and automated text analysis, yet challenges persist, particularly in maintaining context over lengthy text passages and conserving computational resources.
Enter Llama-3-8B-Instruct-80K-QLoRA, an innovative solution developed by researchers from the Beijing Academy of Artificial Intelligence and Renmin University of China. This groundbreaking model extends the contextual scope from 8K to 80K tokens, addressing the crucial need for efficient comprehension of extended text sequences while mitigating computational overhead.
Distinguishing itself through enhanced attention mechanisms and novel training strategies, Llama-3-8B-Instruct-80K-QLoRA leverages the power of GPT-4 to generate training samples for various NLP tasks, including Single-Detail QA, Multi-Detail QA, and Biography Summarization. Fine-tuning with QLoRA, a technique applying LoRA on projection layers during embedding layer training, further enhances its ability to grasp intricate contextual nuances.
By incorporating RedPajama, LongAlpaca, and synthetic data to prevent information loss and bolster contextual understanding, this model achieves remarkable performance milestones. Training on 8xA800 GPUs over 8 hours, the model organizes question-answer pairs into multi-turn conversations, refining its capacity to handle extensive contextual inputs.
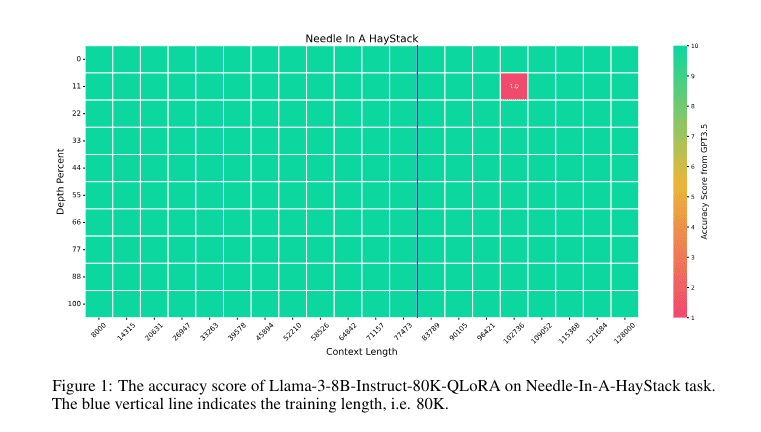
In rigorous evaluations, Llama-3-8B-Instruct-80K-QLoRA showcases unparalleled accuracy, achieving a perfect score in the Needle-In-A-Haystack task across its expansive context length. It outperforms competitors in LongBench benchmarks, except in code completion, and excels in tasks such as LongBookQA and summarization within the InfBench framework. Furthermore, its robust performance in zero-shot evaluations on the MMLU benchmark underscores its efficiency in managing long-context tasks with finesse, cementing its status as a trailblazer in AI-driven language understanding.
Conclusion:
The introduction of Llama-3-8B-Instruct-80K-QLoRA signifies a significant leap forward in AI-driven language understanding. Its ability to efficiently comprehend and maintain context over extended text sequences opens up new possibilities for applications in industries reliant on NLP technologies, such as customer service, content generation, and data analysis. This innovation has the potential to revolutionize how businesses interact with and analyze vast amounts of textual data, paving the way for more intuitive and efficient AI-driven solutions.