
- LLaVA-NeXT, an open-source LMM, revolutionizes multimodal understanding.
- Developed by a collaboration of researchers from top universities and Bytedance.
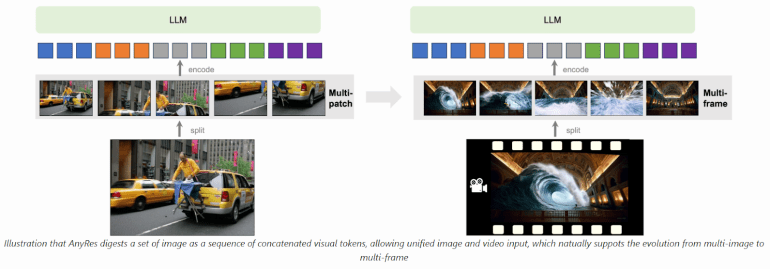
- Utilizes the AnyRes technique for enhanced reasoning and OCR capabilities.
- Surpasses benchmarks like MMMU and MathVista, marking a significant leap.
- Exhibits robust video comprehension capabilities, leveraging AnyRes for modality transfer.
- Implements length generalization techniques for processing longer video sequences.
Main AI News:
In the dynamic pursuit of Artificial General Intelligence (AGI), the significance of Language and Multimodal Models (LLMs and LMMs) cannot be overstated. They serve as the cornerstone of cutting-edge AI, mimicking the cognitive abilities of human minds across a spectrum of tasks. However, amidst this progress, evaluating the capabilities of these models remains a challenge, with fragmented datasets spread across various platforms like Google Drive and Dropbox.
While the lm-evaluation-harness has set a standard for LLM evaluation, there exists a notable void in the assessment of multimodal models. This fragmentation underscores the infancy of multimodal model evaluation, urging the development of a unified framework to comprehensively gauge their performance across diverse datasets.
In response to this pressing need, a collaborative effort from researchers at Nanyang Technological University, University of Wisconsin-Madison, and Bytedance has yielded LLaVA-NeXT, an innovative open-source LMM specifically trained on text-image data. This groundbreaking model incorporates the AnyRes technique, which significantly bolsters reasoning, Optical Character Recognition (OCR), and world knowledge capabilities, thereby showcasing exceptional performance across a range of image-based multimodal tasks.
In benchmark assessments like MMMU and MathVista, LLaVA-NeXT has surpassed its predecessors, including the renowned Gemini-Pro, marking a substantial advancement in multimodal understanding capabilities.
Expanding its horizon to encompass video comprehension, LLaVA-NeXT demonstrates unexpected proficiency, boasting key enhancements that redefine the landscape. Leveraging the power of AnyRes, the model achieves zero-shot video representation, demonstrating an unparalleled ability for modality transfer among LMMs. Moreover, its adeptness at handling longer videos surpasses previous token length constraints through innovative linear scaling techniques.
Through supervised fine-tuning (SFT) and direct preference optimization (DPO), LLaVA-NeXT further enhances its video comprehension capabilities, while its efficient deployment via SGLang enables rapid inference, fostering scalable applications such as million-level video re-captioning. These achievements underscore the model’s state-of-the-art performance and its versatility across multimodal tasks, effectively positioning it as a formidable contender against proprietary models like Gemini-Pro on critical benchmarks.
The AnyRes algorithm within LLaVA-NeXT serves as a versatile framework for processing high-resolution images efficiently. By segmenting images into sub-images using varied grid configurations, it optimizes performance while adhering to token length constraints inherent in LLM architectures. While primarily designed for image processing, with appropriate adjustments, AnyRes can also be adapted for video processing. However, careful consideration of token allocation per frame is imperative to prevent exceeding token limits. Spatial pooling techniques play a pivotal role in optimizing token distribution, striking a balance between frame count and token density. Nevertheless, capturing comprehensive video content remains a challenge, particularly with an increased frame count.
Addressing the necessity to process longer video sequences, LLaVA-NeXT implements length generalization techniques inspired by recent advancements in handling extended sequences in LLMs. By scaling the maximum token length capacity, the model effectively accommodates longer sequences, thereby enhancing its capability to analyze extended video content. Additionally, leveraging DPO harnesses feedback generated by LLMs to train LLaVA-NeXT-Video, resulting in substantial performance improvements. This approach not only offers a cost-effective alternative to acquiring human preference data but also holds promising potential for refining training methodologies in multimodal contexts, paving the way for further advancements in AI research and application.
Conclusion:
The emergence of LLaVA-NeXT signifies a pivotal moment in the market for AI-driven multimodal understanding. Its groundbreaking advancements in both image and video comprehension, coupled with its open-source nature, challenge proprietary models and pave the way for innovative applications across various industries. As businesses seek more robust AI solutions for multimedia tasks, the versatility and performance of LLaVA-NeXT position it as a key player in shaping the future of AI-driven technologies.