
TL;DR:
- Large Language Models (LLMs) have excelled in various tasks, imitating human capabilities.
- LLM-Blender is an innovative framework that leverages the strengths of multiple open-source LLMs for superior performance.
- The framework consists of two modules: PAIRRANKER identifies variations among potential outputs, while GENFUSER merges top-ranked candidates for improved results.
- The MixInstruct benchmark dataset evaluates LLM-Blender’s performance against 11 popular LLMs, demonstrating its significant superiority.
- LLM-Blender has the potential to revolutionize language model deployment and research through ensemble learning.
Main AI News:
Large Language Models (LLMs) have undoubtedly been the talk of the town, showcasing unparalleled performance across a diverse range of tasks. From generating captivating content and providing insightful answers to language translation and text summarization, LLMs have truly emulated human capabilities. Notable names like GPT, BERT, and PaLM have garnered attention for their ability to follow instructions meticulously and tap into vast reservoirs of high-quality data. However, not all LLMs are open-source; models such as GPT4 and PaLM remain enigmatic, concealing their architectures and training data from the public eye.
Enter the world of open-source LLMs, where innovation thrives. Platforms like Pythia, LLaMA, and Flan-T5 have opened up new possibilities for researchers to fine-tune and enhance these models on custom instruction datasets. This has paved the way for the emergence of smaller and more efficient LLMs, such as Alpaca, Vicuna, OpenAssistant, and MPT.
In the dynamic landscape of open-source LLMs, there is no single leader that dominates the market. The best-performing LLM can vary significantly depending on the task at hand. To consistently produce top-notch results for every input, a novel solution has been proposed – the LLM-Blender. Spearheaded by researchers from the Allen Institute for Artificial Intelligence, the University of Southern California, and Zhejiang University, LLM-Blender is an ingenious ensembling framework that capitalizes on the diverse strengths of multiple open-source large language models to achieve consistently superior performance.
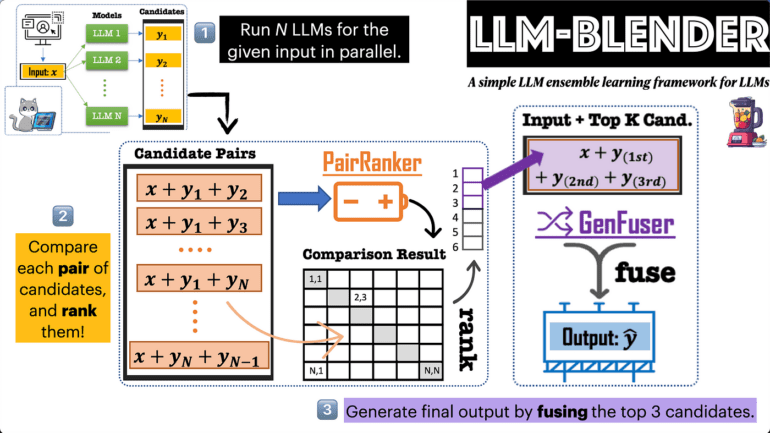
At the heart of LLM-Blender lie two powerful modules – PAIRRANKER and GENFUSER. These modules demonstrate that the optimal LLM for different examples may differ substantially. PAIRRANKER, the first module, excels in identifying subtle variations among potential outputs. Employing an advanced pairwise comparison technique, PAIRRANKER takes the original text and two candidate outputs from different LLMs as inputs. By utilizing cross-attention encoders like RoBERTa, PAIRRANKER determines the quality of the two candidates based on this encoding, enabling precise ranking.
The second module, GENFUSER, takes center stage in merging the top-ranked candidates to create an output that surpasses any single LLM. GENFUSER maximizes the advantages of selected candidates while minimizing their disadvantages, resulting in an output of superior quality.
To put LLM-Blender to the test, the researchers have introduced a benchmark dataset called MixInstruct. This comprehensive dataset combines Oracle pairwise comparisons and various instruction datasets to evaluate the performance of 11 popular open-source LLMs across multiple instruction-following tasks. The dataset comprises training, validation, and test examples, with Oracle comparisons facilitating automatic evaluation and ground truth ranking of candidate outputs. The results demonstrate that LLM-Blender outperforms individual LLMs and baseline techniques by a significant margin. It bridges the gap in performance and establishes itself as the preferred choice for generating high-quality output, surpassing single LLMs and baseline methods.
PAIRRANKER’s precise selections have shown superior performance in reference-based metrics and GPT-Rank, outperforming individual LLM models. GENFUSER’s efficient fusion further elevates the response quality by capitalizing on PAIRRANKER’s top picks.
LLM-Blender’s outstanding performance has not only surpassed individual LLMs like Vicuna but has also revealed its immense potential for enhancing LLM deployment and research through the power of ensemble learning. In the ever-evolving landscape of language models, LLM-Blender stands tall as a game-changer in the business world, setting new standards for language processing and understanding.
Conclusion:
The emergence of LLM-Blender in the market signifies a pivotal shift in the language model landscape. By combining the strengths of various open-source LLMs, it has demonstrated remarkable performance advantages over individual models. This framework opens up new possibilities for businesses and researchers, enabling them to consistently produce high-quality outputs across diverse tasks. As the demand for language processing solutions continues to grow, LLM-Blender positions itself as a game-changer, setting new standards and reshaping the market dynamics. Businesses that adopt this cutting-edge ensembling technology stand to gain a competitive edge in their respective industries, enhancing their capabilities to deliver top-notch content, translations, and summarizations.