
TL;DR:
- LLM360 is an open-source initiative designed to provide complete transparency and reproducibility in Large Language Models (LLMs) by offering access to training code, data, model checkpoints, and intermediate results.
- The project releases two 7B parameter LLMs, AMBER and CRYSTALCODER, along with in-depth documentation on the pre-training dataset and architectural details of the LLM model.
- Memorization scores are introduced to help researchers navigate the complexities of LLMs, and there is a strong emphasis on disclosing the pre-training data and associated risks.
- Benchmark results on four datasets, including ARC, HellaSwag, MMLU, and TruthfulQA, showcase the performance of AMBER and its competitive edge when fine-tuned.
- LLM360 represents a significant step towards transparency and collaboration in the AI research community.
Main AI News:
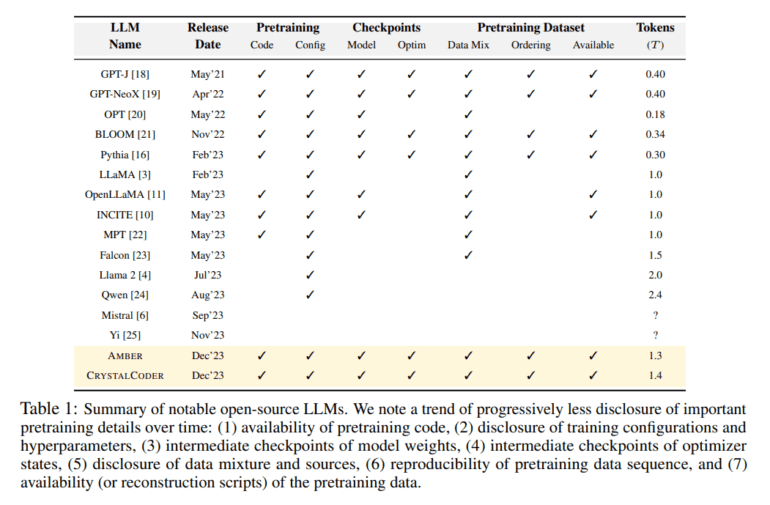
In the realm of open-source Large Language Models (LLMs), options like LLaMA, Falcon, and Mistral have paved the way for AI professionals and scholars. However, these models often come with limitations, offering only selective components and leaving many aspects of their training process shrouded in mystery. This lack of transparency hinders progress in the field and leads to redundant efforts to uncover the intricacies of LLM training.
Enter LLM360, a collaborative effort by researchers from Petuum, MBZUAI, USC, CMU, UIUC, and UCSD. LLM360 aims to revolutionize the world of open-source LLMs by providing complete transparency and reproducibility in the LLM training process. This groundbreaking initiative advocates for sharing not just the end-model weights or inference scripts but also all the crucial elements, including training code, data, model checkpoints, and intermediate results, with the entire community.
Comparable projects like Pythia share similar goals in achieving full reproducibility of LLMs. EleutherAI models, such as GPT-J and GPT-NeoX, have set a precedent by releasing their training code, datasets, and intermediate model checkpoints, demonstrating the immense value of open-source training resources. INCITE, MPT, and OpenLLaMA have also made strides by sharing training code and datasets, with RedPajama contributing intermediate model checkpoints to the mix.
LLM360 takes a giant leap forward by unveiling two impressive 7B parameter LLMs, AMBER and CRYSTALCODER, alongside their training code, data, intermediate checkpoints, and detailed analyses. The research delves deep into the specifics of the pre-training dataset, covering data preprocessing, format, data mixing ratios, and architectural intricacies of the LLM model.
One noteworthy aspect mentioned in the research is the use of memorization scores, introduced in prior work, to aid researchers in finding their way within the vast realm of LLMs. The study also emphasizes the significance of disclosing the data on which LLMs are pre-trained, providing insights into data filtering, processing, and training in order to assess potential risks associated with LLMs.
To put LLM360 to the test, the research presents benchmark results on four datasets: ARC, HellaSwag, MMLU, and TruthfulQA, offering a glimpse into the model’s performance during pre-training. Notably, HellaSwag and ARC exhibit a consistent increase in evaluation scores during pre-training, while TruthfulQA sees a decline. The MMLU score experiences an initial decrease, followed by a steady rise. AMBER, one of the stars of LLM360, demonstrates competitive performance in scores such as MMLU, although it falls slightly behind in ARC. However, when fine-tuned, AMBER models shine brightly, outperforming other similar models in the field.
Conclusion:
LLM360 represents a significant advancement in open-source language models, setting a new standard for transparency and collaboration in the AI research community. By sharing comprehensive training resources and benchmarking results, it empowers professionals and scholars to push the boundaries of AI, potentially catalyzing innovation and market growth in the field.