
TL;DR:
- Large Language Models (LLMs) have transformed NLP research, but their extensive parameter tuning requires significant GPU resources.
- Recent advancements in parameter-efficient fine-tuning techniques like LoRA and Prefix-tuning have made LLM tuning more accessible.
- Researchers have developed LOMO, an AI optimizer that combines gradient computation and parameter update, significantly reducing memory usage.
- LOMO achieves this by eliminating the need for optimizer states, reducing gradient tensor memory consumption, and incorporating gradient normalization and loss scaling.
- LOMO enables comprehensive parameter fine-tuning in resource-constrained environments and has been successfully applied to train a 65B model with minimal GPU resources.
- The empirical findings validate the efficiency of LOMO and its downstream performance in optimizing LLMs with many parameters.
Main AI News:
In the realm of Natural Language Processing (NLP), the advent of Large Language Models (LLMs) has been nothing short of transformative. These models have astounded us with their remarkable abilities, such as emergence and grokking, while continuously pushing the boundaries of model size. NLP research has been revolutionized by training LLMs with billions of parameters, ranging from 30B to 175B. However, this progress has posed a challenge for smaller labs and businesses, as fine-tuning LLMs often demands significant GPU resources, such as 880GB machines.
Fortunately, recent advancements have made it possible for resource-constrained environments to partake in LLM tuning. Techniques like LoRA and Prefix-tuning have emerged as parameter-efficient fine-tuning methods, allowing for more feasible exploration in this field of research. While complete parameter fine-tuning has traditionally been considered more effective, both approaches offer viable solutions. The key question is how to accomplish comprehensive parameter fine-tuning when resources are limited. To tackle this challenge, researchers have focused on optimizing the memory utilization of LLMs across four key characteristics: activation, optimizer states, gradient tensors, and parameters.
Their investigation has led to three major breakthroughs:
- Reevaluating the role of optimizers: Through a meticulous analysis of optimizer algorithms, they have discovered that Stochastic Gradient Descent (SGD) can serve as a suitable substitute for fine-tuning LLM parameters. Since SGD doesn’t retain intermediate states, it becomes possible to eliminate the entire portion of optimizer states. This realization significantly contributes to reducing memory overhead.
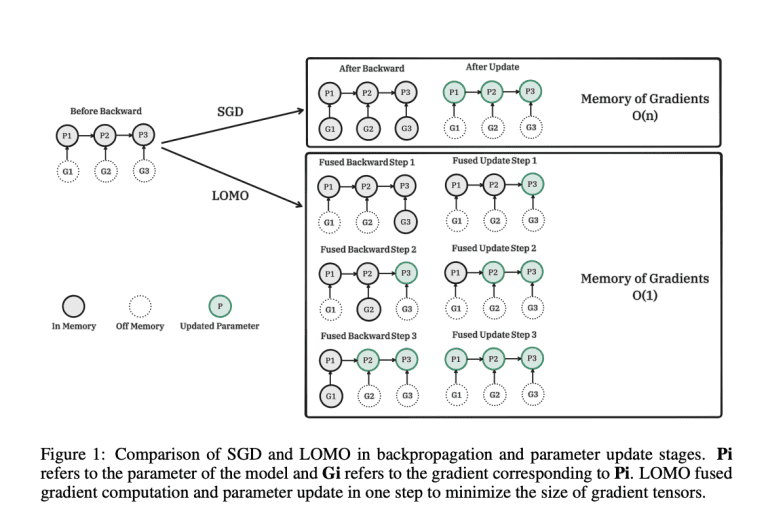
- Introducing LOMO: The researchers propose a novel optimizer, LOMO, as illustrated in Figure 1. LOMO dramatically reduces the memory consumption of gradient tensors, bringing it down to zero, which is equivalent to the memory usage of the largest gradient tensor. This innovation is a game-changer in optimizing LLMs, making efficient memory utilization a reality.
- Enhancing training stability: To ensure stable mix-precision training with LOMO, the researchers incorporate gradient normalization and loss scaling, while shifting certain calculations to full precision during the training process. This combination effectively balances memory requirements with training performance, achieving optimal results.
By implementing these advancements, the researchers have successfully mitigated the memory consumption associated with complete parameter fine-tuning, bringing it closer to the level of inference. Importantly, they have ensured that the fine-tuning function remains unaffected when utilizing LOMO for memory conservation, as the parameter update process aligns with that of SGD. The team at Fudan University has empirically demonstrated the effectiveness of LOMO by training a 65B model using only 8 RTX 3090 GPUs. Their evaluation of memory utilization and throughput capabilities highlights the immense potential of LOMO. Furthermore, they have applied LOMO to fine-tune the entire parameter set of LLMs on the SuperGLUE dataset collection, successfully validating its downstream performance.
The contributions of their research can be summarized as follows:
- Theoretical breakthrough: The researchers present a theoretical study that establishes SGD as a viable method for adjusting all parameters of LLMs. This indicates that the obstacles that once hindered the widespread adoption of SGD may not be as significant when optimizing LLMs.
- LOMO: They introduce LOMO, a cutting-edge low-memory optimization technique that significantly reduces GPU memory utilization while preserving the fine-tuning process. This breakthrough ensures that memory constraints no longer impede the advancement of LLMs.
- Empirical evidence: Through meticulous analysis of memory utilization and throughput performance, the researchers empirically demonstrate the efficiency of LOMO in resource-constrained environments. They provide compelling evidence of its effectiveness through downstream performance assessments.
The researchers have made their code implementation available on GitHub, making it accessible for further exploration and application. LOMO represents a groundbreaking advancement in the field of AI optimization, revolutionizing memory utilization for Large Language Models and empowering researchers and businesses alike to participate in cutting-edge NLP research.
Conclusion:
The development of LOMO and its application in optimizing Large Language Models have significant implications for the market. The ability to achieve comprehensive parameter fine-tuning with reduced memory consumption opens doors for smaller labs and businesses to participate in NLP research without requiring expensive GPU resources. LOMO’s efficiency in optimizing LLMs with billions of parameters demonstrates its potential to drive advancements in natural language processing and facilitate the development of more powerful and accessible AI models. This breakthrough brings opportunities for innovation and growth in the market, enabling organizations to leverage the capabilities of LLMs and unlock new possibilities in language understanding and generation.