
TL;DR:
- Large language models (LLMs) have revolutionized natural language processing.
- LLMs have limitations in handling long-form material beyond a fixed session.
- LONGMEM proposes a framework to address the memory staleness problem in LLMs.
- The framework utilizes a decoupled memory module and a residual side network (SideNet).
- LONGMEM enables LLMs to store and access long-form prior context or knowledge.
- It enhances long-text modeling, in-context learning, and natural language understanding.
- Experimental results demonstrate superior performance compared to baselines.
- LONGMEM improves the ability of LLMs to represent long-context language.
Main AI News:
In the realm of natural language processing, large language models (LLMs) have brought about significant advancements in understanding and generation tasks, sparking a revolution in the field. These LLMs have harnessed the power of self-supervised training over extensive corpora, allowing them to gather information from a fixed-sized local context and demonstrate emerging capabilities such as zero-shot prompting, in-context learning, and Chain-of-Thought (CoT) reasoning. However, the input length limitation of present LLMs hinders their ability to generalize to real-world applications that demand extended horizontal planning and the handling of long-form material beyond a fixed session.
To address the challenge of input length, one straightforward solution is to scale up the input context length. For instance, GPT-3 elevates the input length from 1k tokens in GPT-2 to 2k tokens, enabling improved long-range interdependence. Nevertheless, the dense attention within the context is severely constrained by the quadratic computing complexity of Transformer self-attention. Consequently, techniques like in-context sparse attention have emerged as a new area of research, aiming to alleviate the quadratic cost associated with self-attention. However, most of these techniques require computationally extensive training from scratch.
While the Memorising Transformer (MemTRM) has been a notable study in this regard, it approximates in-context sparse attention by employing dense attention for both in-context tokens and memorized tokens retrieved from a non-differentiable memory in Transformers. MemTRM achieves significant perplexity benefits when modeling large books or papers, as it scales up the language model to handle up to 65k tokens. However, MemTRM encounters the challenge of memory staleness during training. In other words, cached representations in memory may exhibit distributional changes when the model parameters are altered, thereby reducing the effectiveness of memory augmentation.
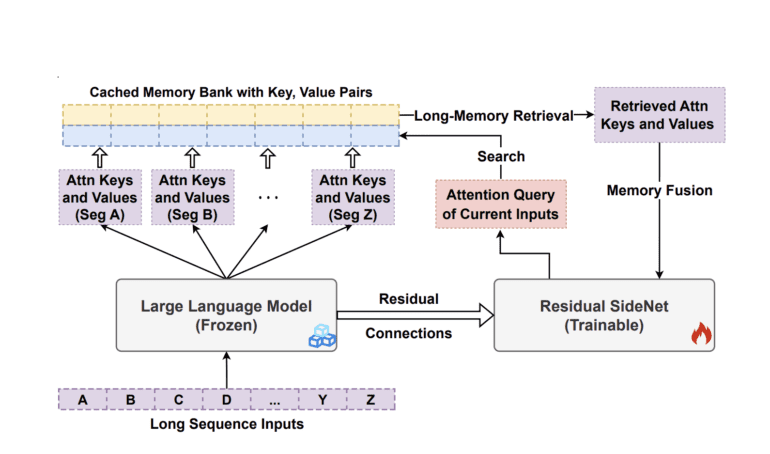
In their recent paper, researchers from UC Santa Barbara and Microsoft Research propose an innovative framework called LONGMEM. This framework empowers language models to store long-form prior context or knowledge into a non-differentiable memory bank and leverage it through a decoupled memory module, effectively addressing the memory staleness problem. To achieve decoupled memory, the authors introduce a groundbreaking residual side network (SideNet). They employ a frozen backbone LLM to extract attention keys and values from the previous context, storing them in the memory bank. The resulting attention query of the current input is then used within the SideNet’s memory-augmented layer to access cached information from earlier contexts. These memory augmentations are subsequently fused into the learning hidden states through a joint attention process.
To facilitate better knowledge transfer from the pretrained backbone LLM, the researchers establish cross-network residual connections between the SideNet and the frozen backbone LLM. By repeatedly training the residual SideNet to extract and fuse memory-augmented long-context, the pretrained LLM can effectively utilize long-contextual memory. The decoupled memory system presented in LONGMEM offers two primary advantages. Firstly, it addresses the issue of memory staleness by separating memory retrieval and fusion from the encoding of prior inputs into memory. The frozen backbone LLM solely functions as the encoder of long-context knowledge, while the residual SideNet acts as the retriever and reader of memory. Secondly, directly modifying the LLM with memory augmentations proves computationally inefficient and leads to catastrophic forgetting. LONGMEM overcomes this challenge by keeping the backbone LLM frozen during the effective memory-augmented adaption stage. Depending on the requirements, LONGMEM can accommodate various types of long-form text and information, inputting them into the memory bank.
The researchers specifically focus on two illustrative instances to demonstrate the effectiveness of LONGMEM. Firstly, they explore memory-augmented in-context learning with thousands of task-relevant demonstration examples. Secondly, they delve into language modeling using full-length book contexts. Through extensive evaluation, the proposed LONGMEM consistently outperforms strong baselines in terms of its capacity for long-text modeling and in-context learning. Experimental findings reveal that LONGMEM achieves a perplexity reduction of -1.38 ~ -1.62 over different length splits of the Gutenberg-2022 corpus, thus substantially improving the ability of LLMs to represent long-context language. Remarkably, LONGMEM surpasses the current state-of-the-art performance of 40.5% identification accuracy on ChapterBreak, a challenging benchmark for long-context modeling, outperforming even the strongest x-former baselines. Lastly, in the context of memory enhancement, LONGMEM demonstrates remarkable in-context learning benefits on common natural language understanding (NLU) tasks, outshining MemTRM and baselines without memory enhancement.
Conclusion:
The LONGMEM framework presents a significant advancement in the field of language processing. By overcoming the limitations of LLMs in handling long-form material, LONGMEM opens up new opportunities in various applications such as extended horizontal planning, long-text modeling, and in-context learning. This breakthrough has the potential to shape the market by providing more accurate and contextually rich language models, leading to enhanced natural language understanding and generation. Businesses in sectors such as customer support, content generation, and language-based AI applications can benefit from the improved capabilities of LLMs powered by LONGMEM, enabling them to deliver more sophisticated and context-aware solutions to their customers.