
TL;DR:
- Magicoder, developed by researchers from the University of Illinois and Tsinghua University, redefines open-source code generation.
- It outperforms existing LLMs in Python text-to-code generation, multilingual coding, and data science program language modeling.
- Magicoder leverages instruction tuning, OSS-INSTRUCT, and diverse seed code snippets from GitHub to ensure real-world relevance.
- Evaluation using benchmarks like HumanEval and MBPP highlights Magicoder’s competitive edge.
- The enhanced version, MagicoderS, sets new standards in code generation, outperforming models of similar or larger sizes.
- Magicoder’s commitment to open-source principles signifies a major shift in the LLM market.
Main AI News:
The University of Illinois at Urbana-Champaign and Tsinghua University have jointly unveiled a groundbreaking solution to the challenge of generating unbiased and high-quality coding challenges from open-source code snippets. Magicoder, the brainchild of these visionary researchers, has set a new benchmark in the world of Large Language Models (LLMs) for code.
In a realm where giants like CodeGen, CodeT5, StarCoder, and CODELLAMA have long been regarded as the pinnacle of LLMs’ code generation capabilities, Magicoder has emerged as a game-changer. Its innovation lies in the strategic use of instruction tuning, a technique that fine-tunes pretrained LLMs with instruction-response pairs. Methods like SELF-INSTRUCT and Evol-Instruct have further bolstered Magicoder’s prowess by generating synthetic data for instruction tuning.
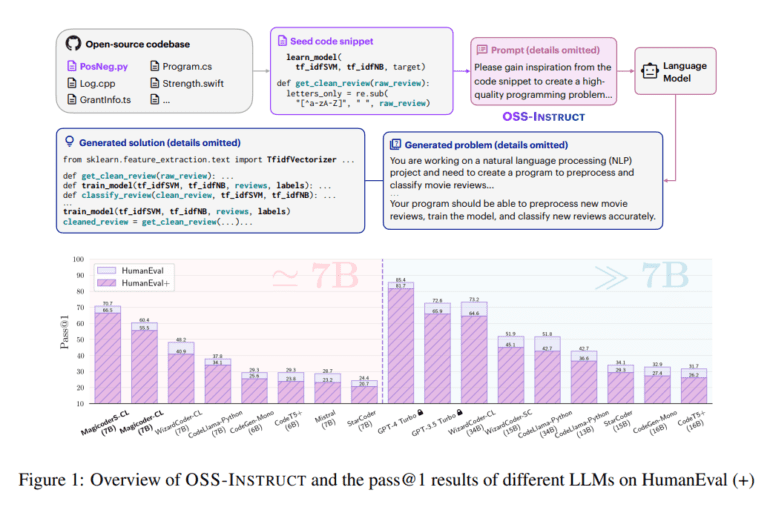
One of Magicoder’s distinguishing features is its reliance on 75,000 synthetic instruction data created using OSS-INSTRUCT, an ingenious approach that enriches LLMs with open-source code snippets. This not only ensures the generation of high-quality instruction data for code but also prompts LLMs to craft coding problems and solutions based on seed code snippets from GitHub. The result is a level of diversity and real-world relevance that is unparalleled in the field.
Benchmarks like HumanEval and MBPP have been employed to gauge Magicoder’s performance, with a particular focus on the pass1 metric. The INSTRUCTOR tool is utilized to categorize OSS-INSTRUCT-generated data based on embedding similarity. Robustness is ensured through data cleaning techniques, including decontamination and prompt filtering.
Despite its modest parameter size of no more than 7 billion, Magicoder has managed to outperform advanced code models in Python text-to-code generation, multilingual coding, and data science program language modeling. But the story doesn’t end there. MagicoderS, the enhanced version, takes performance to new heights, surpassing models of similar or larger sizes across various benchmarks. MagicoderS-CL-7B, in particular, stands out by achieving cutting-edge results in the realm of code models, solidifying its position as a robust and superior code generation powerhouse.
In a landscape where innovation and excellence are the keys to success, Magicoder has not only unlocked new possibilities in code generation but has also set a standard that others can only aspire to match. With its commitment to open-source principles and a relentless pursuit of excellence, Magicoder has truly changed the game in the world of Large Language Models for code.
Conclusion:
Magicoder’s emergence as a powerful and open-source-driven LLM for code generation has far-reaching implications for the market. It not only sets a new benchmark for performance but also signifies a shift towards open-source principles in the industry, potentially reshaping the dynamics of the LLM market by promoting transparency and excellence.