
TL;DR:
- MAmmoTH series of open-source LLMs designed for math problem-solving.
- Closed-source models dominate, but MAmmoTH aims to bridge the gap.
- Two strategies: ongoing pre-training and fine-tuning for dataset uniqueness.
- Innovative MathInstruct dataset blends Chain-of-Thought (CoT) and PoT approaches.
- MAmmoTH models show unparalleled promise as mathematical generalists.
- Testing across various datasets proves remarkable efficiency and generalization.
- MAmmoTH outperforms open-source competitors, improving accuracy significantly.
Main AI News:
In the realm of modern large language models (LLMs), mathematical reasoning stands as a pinnacle of focus and innovation. This article delves into the world of MAmmoTH, a remarkable series of open-source LLMs specifically engineered to excel in general math problem-solving. Within this landscape, a clear dichotomy prevails between closed-source and open-source LLMs, with closed-source giants like GPT-4, PaLM-2, and Claude 2 reigning supreme in renowned mathematical reasoning benchmarks such as GSM8K and MATH. Meanwhile, open-source contenders like Llama, Falcon, and OPT find themselves lagging behind.
To bridge this gap, two distinct approaches have emerged as beacons of progress. The first entails ongoing pre-training, a strategy employed by Galactica and MINERVA, involving the training of an LLM on a staggering 100 billion tokens of web data intricately linked to mathematics. Although computationally demanding, this method significantly bolsters a model’s capacity for scientific reasoning across the board.
The second approach centers on fine-tuning methods tailored to the unique attributes of each dataset. Techniques like rejection sampling fine-tuning (RFT) and WizardMath have proven highly effective within their respective domains but fall short when applied to broader mathematical contexts that necessitate profound reasoning capabilities.
Recent research endeavors undertaken by esteemed institutions such as the University of Waterloo, the Ohio State University, HKUST, the University of Edinburgh, and IN.AI have explored a novel and lightweight math instruction-tuning technique. This approach seeks to enhance the mathematical reasoning abilities of LLMs at a general level, transcending the confines of fine-tuning tasks.
Presently, the predominant methodologies rely heavily on Chain-of-Thought (CoT) paradigms, which articulate mathematical problem-solving in natural language steps. Yet, these methods encounter limitations in terms of computational precision and the handling of intricate mathematical or algorithmic reasoning challenges. On the flip side, code-based strategies like PoT and PAL leverage external resources to streamline mathematical problem-solving processes. However, PoT exhibits constraints when confronted with more abstract reasoning scenarios, particularly those involving commonsense reasoning, formal logic, and abstract algebra, where pre-existing APIs may be lacking.
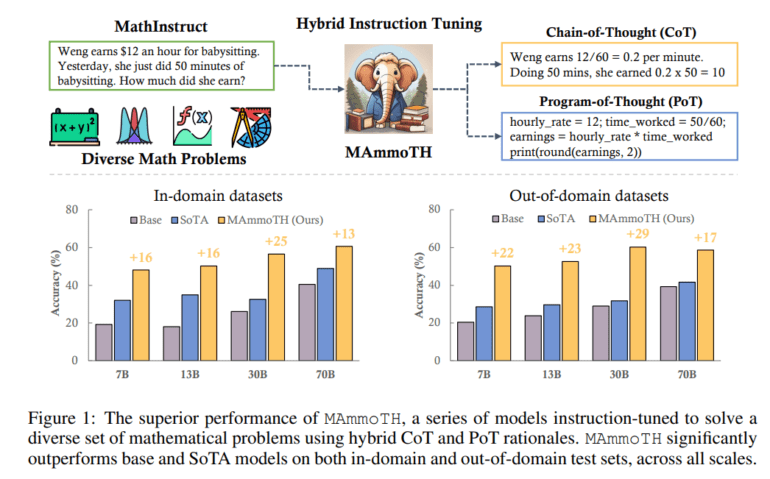
In a bid to harness the strengths of both CoT and PoT, the research team introduces MathInstruct, an innovative hybrid instruction-tuning dataset for mathematics. MathInstruct boasts comprehensive coverage of diverse mathematical domains and complexity levels, blending the strengths of both CoT and PoT rationales.
The foundation for MathInstruct is laid upon six newly curated datasets and seven pre-existing ones. From a modeling perspective, approximately 50 unique models have been trained and evaluated, with baselines ranging from 7 billion to a staggering 70 billion parameters. These experiments aim to unravel the impact of varied input-output formats and data sources.
The results are nothing short of astonishing. These models, born from the synergy of diverse mathematical rationales, exhibit unparalleled promise as mathematical generalists. Researchers subjected MAmmoTH to rigorous testing across a spectrum of datasets, spanning from in-domain (IND) to out-of-domain (OOD) scenarios, including GSM8K, MATH, AQuA-RAT, and NumGLUE. The outcome was nothing short of remarkable, as these models significantly enhance the efficiency of open-source LLMs in mathematical reasoning and showcase superior generalization capabilities compared to state-of-the-art approaches.
Notable achievements include the 7-billion-parameter MAmmoTH model, which outperforms WizardMath (an open-source MATH state-of-the-art model) by a staggering factor of 3.5 (35.2% vs. 10.7%) on the fiercely competitive MATH dataset. Meanwhile, the 34-billion-parameter MAmmoTH-Coder, fine-tuned on Code Llama, surpasses the performance of GPT-4 (employing CoT) in mathematical reasoning. Both MAmmoTH and MAmmoTH-Coder represent substantial leaps forward, significantly elevating the accuracy of open-source models beyond what was previously attainable.
Conclusion:
The MAmmoTH series of open-source LLMs, with its novel MathInstruct dataset and hybrid approach, promises to revolutionize mathematical problem-solving. This advancement signifies a major shift in the market, offering enhanced efficiency and accuracy in mathematical reasoning tasks, thereby opening up new possibilities for applications across industries.