
TL;DR:
- MathVista is a benchmark assessing mathematical reasoning in AI models.
- It combines mathematical and graphical tasks within visual contexts.
- Existing benchmarks focus on text-based tasks, limiting AI’s visual reasoning capabilities.
- MathVista reveals significant performance gaps in AI models compared to human abilities.
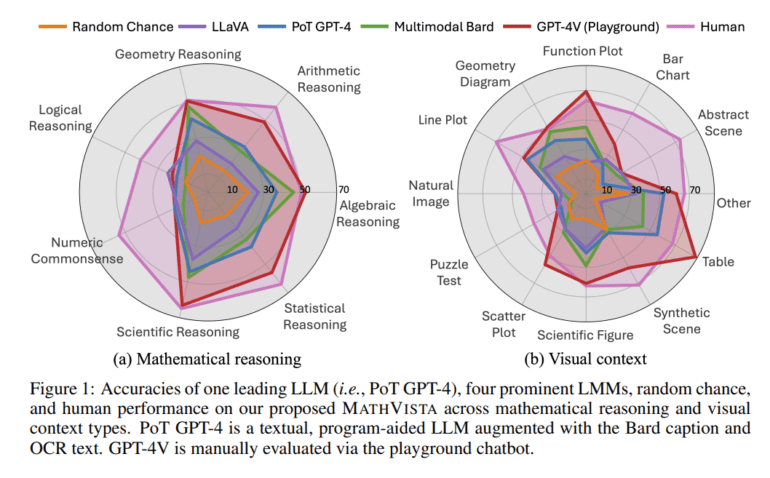
- Multimodal Bard is the top performer with 34.8% accuracy, but human performance is at 60.3%.
- Text-only LLMs achieve 29.2% accuracy, while augmented LLMs reach 33.9%.
- Open-source LMMs like IDEFICS and LLaVA face challenges in math reasoning and text recognition.
- MathVista is vital for developing versatile AI agents with mathematical and visual reasoning abilities.
Main AI News:
In the realm of artificial intelligence, the fusion of mathematical prowess and visual acumen has long been an elusive aspiration. Enter MathVista, a groundbreaking benchmark that seeks to evaluate the mathematical reasoning capabilities of Large Language Models (LLMs) and Large Multimodal Models (LMMs) within a visually enriched context. This revolutionary standard amalgamates an array of mathematical and graphical challenges, drawing from both existing and novel datasets. In our previous exploration, we highlighted the pressing need for advancements in this arena, as 11 prominent models, including LLMs, tool-augmented LLMs, and LMMs, demonstrated a noticeable performance gap when compared to human aptitude. The significance of MathVista extends far beyond mere metrics; it is instrumental in propelling the development of versatile AI agents endowed with the powers of mathematical and visual reasoning.
Traditionally, benchmarks gauging the mathematical reasoning skills of LLMs have been restricted to text-based tasks, with some, like GSM-8K, showing diminishing returns in performance improvements. This limitation has necessitated the emergence of robust multimodal benchmarks in scientific domains. Benchmarks such as Visual Question Answering (VQA) have broadened the horizons of visual reasoning for LMMs, encompassing an eclectic array of visual content beyond natural images. The pivotal role played by generative foundation models in solving diverse tasks sans fine-tuning cannot be understated. Additionally, specialized pre-training techniques have enhanced chart reasoning within visual contexts, underscoring the burgeoning significance of these models in practical applications.
The realm of mathematical reasoning stands as a cornerstone of human intelligence, wielding its influence across diverse fields, including education, data analysis, and scientific discovery. However, existing benchmarks for AI-driven mathematical reasoning predominantly revolve around text-based scenarios, devoid of rich visual contexts. To address this lacuna, a consortium of researchers from prestigious institutions such as UCLA, the University of Washington, and Microsoft Research presents MathVista—a comprehensive benchmark that marries a spectrum of mathematical and graphical challenges with the evaluation of reasoning capabilities inherent in foundation models. MathVista spans multiple reasoning paradigms, primary tasks, and a kaleidoscope of visual contexts, with the ultimate goal of elevating the mathematical reasoning prowess of models for real-world applications.
MathVista’s distinctive approach revolves around a taxonomy that encompasses diverse task types, reasoning skills, and visual contexts, meticulously curated from a blend of existing and novel datasets. It places models under the spotlight, demanding deep visual comprehension and compositional reasoning prowess. Preliminary assessments conducted on GPT-4V have yielded intriguing insights into the formidable challenges posed by MathVista, emphasizing its profound significance in the landscape of AI development.
The results unveiled by MathVista are nothing short of illuminating. The standout performer, Multimodal Bard, achieves an admirable accuracy rate of 34.8%, yet it pales in comparison to the lofty 60.3% human performance benchmark. Text-only LLMs, including the 2-shot GPT-4, exhibit commendable results with an accuracy rate of 29.2%. Augmented LLMs, equipped with image captions and OCR text, outperform their counterparts, as evidenced by the 2-shot GPT-4’s impressive 33.9% accuracy rate. In stark contrast, open-source LMMs such as IDEFICS and LLaVA grapple with underwhelming performance due to their limitations in mathematical reasoning, text recognition, shape detection, and chart understanding.
Conclusion:
MathVista stands as a testament to the relentless pursuit of excellence in the realm of AI’s visual and mathematical reasoning. It heralds a new era where machines and models are challenged to bridge the gap between human ingenuity and artificial intelligence. As we navigate the complex intersections of mathematics and visuals, MathVista paves the way for AI’s evolution towards more sophisticated and versatile problem-solving capabilities, ultimately shaping the landscape of AI-driven applications in profound ways.