
- Alibaba’s C4 addresses inefficiencies in large-scale parallel training, targeting hardware failures and network congestion.
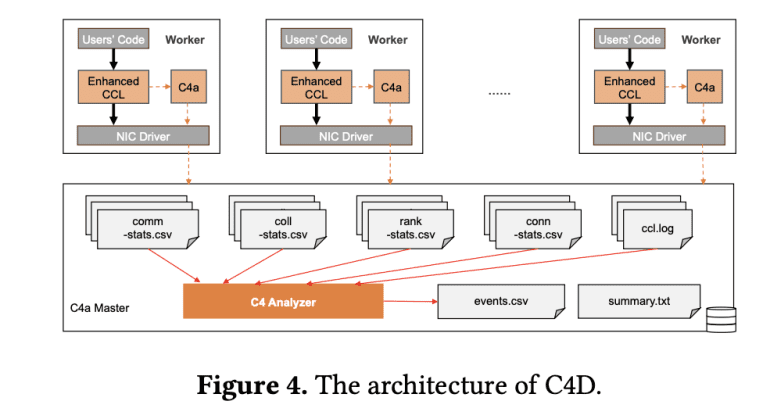
- C4 consists of two subsystems: C4D for diagnosis and C4P for performance optimization.
- C4 enhances training stability by detecting errors in real-time and optimizing network traffic.
- Real-world deployment of C4 reduces error-induced overhead by 30% and improves runtime performance by 15%.
- Evaluation metrics include throughput increase and error reduction across various training tasks.
Main AI News:
Alibaba’s groundbreaking solution, C4, is revolutionizing large-scale parallel training efficiency, addressing significant challenges faced by the training of Large Language Models (LLMs) such as GPT-3 and Llama. Inefficiencies stemming from hardware failures and network congestion have long plagued this process, leading to wasted GPU resources and prolonged training durations. These issues not only hinder progress in AI research but also impede the feasibility of training highly complex models.
Traditionally, basic fault tolerance and traffic management strategies have been employed to mitigate these challenges, but they come with limitations. These methods often lack real-time efficiency, requiring extensive manual intervention for fault diagnosis and network traffic management. Moreover, they struggle to cope with the demands of shared physical clusters, resulting in congestion and reduced performance scalability.
Enter C4, a novel approach developed by Alibaba’s research team, consisting of two integral subsystems: C4D (C4 Diagnosis) and C4P (C4 Performance). C4D ensures training stability by promptly detecting system errors, isolating faulty nodes, and facilitating quick restarts from the last checkpoint. On the other hand, C4P optimizes communication performance by effectively managing network traffic, thereby reducing congestion and maximizing GPU utilization. This comprehensive solution represents a significant advancement in the field, offering unparalleled efficiency and accuracy compared to existing methods.
At the core of the C4 system lies its utilization of predictable communication patterns inherent in collective operations during parallel training. C4D enhances the collective communication library to monitor operations and detect potential errors, swiftly isolating suspect nodes to minimize downtime. Meanwhile, C4P employs innovative traffic engineering techniques to balance network traffic distribution across multiple paths, dynamically adapting to network changes.
Real-world deployment of the C4 system across large-scale AI training clusters has yielded impressive results. Error-induced overhead has been slashed by approximately 30%, while runtime performance has seen a remarkable enhancement of about 15%. These tangible improvements underscore the transformative impact of C4 on the efficiency and efficacy of large-scale parallel training.
Evaluation of C4’s effectiveness focused on key performance metrics, including throughput and error reduction. The findings, illustrated in the accompanying figure, demonstrate substantial performance enhancements across various training jobs. Particularly noteworthy is the up to 15.95% increase in throughput achieved by C4P for tasks with high communication overhead. Comparative analysis against existing baselines, as detailed in the provided table, further emphasizes the superiority of the C4 approach in terms of efficiency and error handling.
Conclusion:
The introduction of Alibaba’s C4 marks a significant leap forward in the efficiency of large-scale parallel training, mitigating the impact of hardware failures and network congestion. This innovative solution not only enhances training stability but also boosts overall performance, promising substantial benefits for the AI market by enabling more efficient and scalable model training.