
- MEGALODON emerges as a pioneering model for handling sequences of unlimited length in natural language processing.
- It integrates Complex Exponential Moving Average (CEMA) and timestep normalization to reduce computational load and enhance scalability.
- The model outperforms traditional Transformer architectures, showcasing superior efficiency and effectiveness across diverse linguistic tasks.
- Rigorous testing on various language processing benchmarks validates MEGALODON’s advanced processing capabilities.
- Benchmark evaluations against datasets designed for long-context scenarios affirm MEGALODON’s efficacy and versatility.
Main AI News:
In the realm of computational advancements, the demand for adept handling of extensive sequential data reigns supreme. Nowhere is this more evident than in natural language processing, where the ability to seamlessly navigate lengthy text streams while retaining context stands as a critical challenge. The prevalent reliance on Transformer architectures, while effective, often falters due to its quadratic computational complexity, hindering efficient processing.
Addressing this challenge head-on, researchers have explored alternatives like linear attention mechanisms and state space models to mitigate computational costs. However, these solutions frequently come at the expense of performance. Enter LLAMA and MEGA, with their innovative approaches like gated attention mechanisms and exponential moving averages. While promising, these models encounter hurdles in scaling and efficiency, especially when confronted with large-scale pretraining and handling extended data sequences.
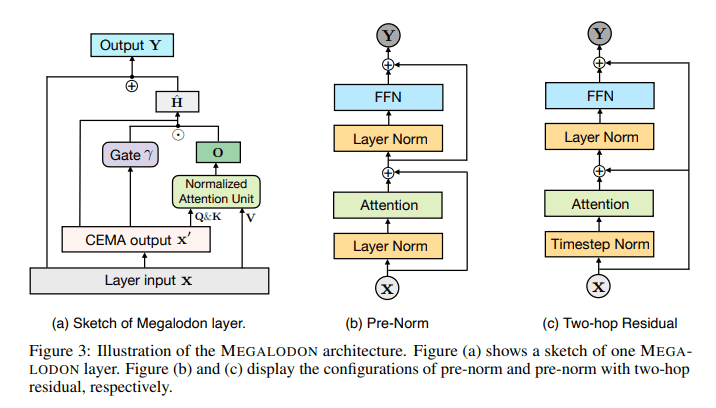
Introducing MEGALODON, a collaborative effort from Meta, the University of Southern California, Carnegie Mellon University, and the University of California San Diego. This groundbreaking model is engineered to tackle sequences of boundless length—an unparalleled capability in the field. By harnessing the power of Complex Exponential Moving Average (CEMA) and timestep normalization, MEGALODON reduces computational load and enhances scalability, setting itself apart from traditional Transformers notorious for their quadratic computational growth.
MEGALODON integrates a trio of technical components: CEMA, timestep normalization, and a normalized attention mechanism. These elements are instrumental in efficiently modeling long sequences with minimal memory overhead. Rigorous testing across various language processing benchmarks, from multi-turn conversations to extensive language modeling tasks, showcases MEGALODON’s prowess. Benchmark evaluations against datasets tailored for long-context scenarios, such as Scrolls and PG19, underscore its efficacy and versatility.
Quantifiable performance improvements further solidify MEGALODON’s position. With a training loss of 1.70, it stands between LLAMA2-7B and LLAMA2-13B, outperforming standard Transformer models on specific benchmarks. For instance, MEGALODON achieves a lower perplexity rate of 23 on the Scrolls dataset, surpassing the Transformer’s score of 30. These results underscore MEGALODON’s advanced processing capabilities for handling lengthy sequential data, reinforcing its efficiency and effectiveness across diverse linguistic tasks.
Conclusion:
The introduction of MEGALODON represents a significant advancement in sequence modeling, particularly in the realm of natural language processing. Its ability to efficiently handle sequences of unlimited length while maintaining high performance levels indicates a promising direction for the market. Organizations leveraging MEGALODON can expect enhanced efficiency and effectiveness in processing extensive sequential data, thereby opening up new possibilities for advanced language processing applications.