
TL;DR:
- MemWalker, a novel method developed by Princeton and Meta AI, tackles the challenge of processing longer input sequences in language models.
- It adopts a unique approach by constructing a memory tree from lengthy text, allowing for efficient navigation.
- MemWalker outperforms other methods in handling extended context questions, offering rapid text processing and error correction.
- However, it faces scalability issues with extremely long sequences, requires large LLMs, and is limited to zero-shot prompting.
- MemWalker promises exciting possibilities for future research, including its adaptation to various data structures.
Main AI News:
In the ever-evolving landscape of large language models (LLMs), the quest for processing longer input sequences has become increasingly paramount. Princeton University and Meta AI researchers have now introduced MemWalker, a groundbreaking method that addresses the challenges of handling extensive text and conversation contexts.
The Transformer architecture, coupled with self-attention mechanisms, has propelled LLMs to unprecedented heights. However, as the length of input sequences grows, so does the burden on the self-attention mechanism to manage an expanding pool of memories. While various strategies, including compact attention schemes, positional embeddings, and recurrent mechanisms, have been employed to mitigate this issue, inherent limitations persist.
MemWalker takes a fresh approach by treating the model’s finite context window as an interactive agent. This innovative method comprises two essential steps: memory tree construction and guided navigation.
Firstly, MemWalker dissects lengthy materials into manageable segments, allowing the LLM to process them effectively. Each segment’s information is distilled into a unified summary node. From these summary nodes, a hierarchical tree structure is constructed, enabling the model to navigate through the text seamlessly.
When faced with a user inquiry, MemWalker initiates from the tree’s root and systematically evaluates each branch, identifying the path that holds the answers. This novel approach empowers MemWalker to swiftly process extensive texts, extracting crucial information without requiring user intervention.
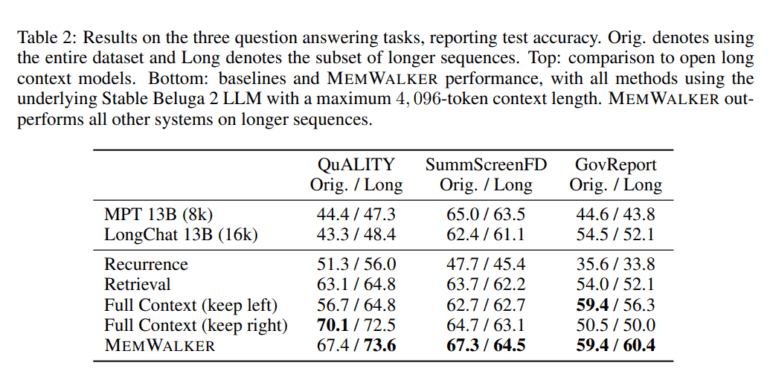
In comparative evaluations, MemWalker surpasses existing methods such as recurrence, retrieval, and vanilla LLM baselines when confronted with extended context questions. Even systems designed to handle 8,000 to 16,000 tokens fall short of MemWalker’s performance. Notably, MemWalker exhibits the ability to make navigation decisions, employ working memory, and rectify early-stage errors.
Despite its remarkable capabilities, MemWalker does face some limitations. Firstly, the scalability of memory tree generation may pose challenges with extremely long sequences. Additionally, MemWalker’s effectiveness hinges on the LLM’s size, requiring models with over 70 billion parameters. Furthermore, its interactive reading capabilities are confined to zero-shot prompting, devoid of fine-tuning.
Conclusion:
The introduction of MemWalker represents a significant leap forward in the field of language models. Its innovative approach to handling lengthy texts and context-rich conversations has the potential to revolutionize the market for natural language processing solutions. Businesses can now harness the power of MemWalker to efficiently analyze and extract valuable insights from extensive textual data, paving the way for more sophisticated applications in various industries. While some limitations exist, the promise of MemWalker opens up exciting possibilities for the future of language processing technologies.