
TL;DR:
- AnyMAL, a multimodal language model by Meta AI, integrates text, images, videos, audio, and motion data seamlessly.
- Addresses the challenge of AI understanding diverse sensory inputs, crucial for human-computer interaction and content generation.
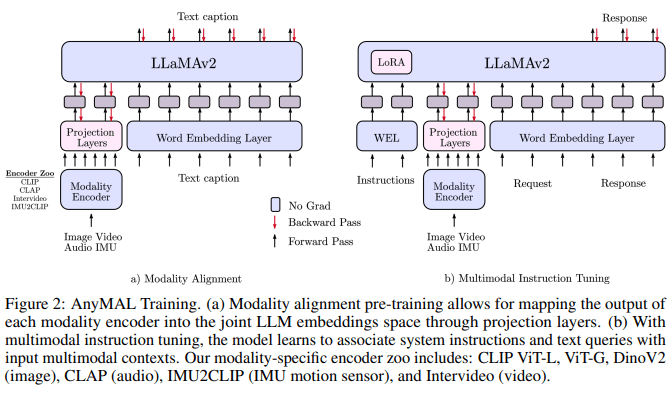
- AnyMAL’s methodology includes the Multimodal Instruction Tuning dataset (MM-IT) for training.
- Excels in creative writing, practical instructions, and factual knowledge tasks.
- Enables practical recommendations based on visual context.
- AnyMAL signifies a new era in AI, enhancing human-machine interaction across industries.
Main AI News:
The realm of artificial intelligence has long grappled with a central challenge: enabling machines to comprehend and generate human language while seamlessly integrating various sensory inputs, including images, videos, audio, and motion signals. This intricate puzzle holds profound implications across a spectrum of applications, encompassing human-computer interaction, content creation, and accessibility. Conventional language models have predominantly fixated on textual inputs and outputs, thereby constraining their ability to grasp and engage with the diverse modalities of human interaction. Acknowledging this limitation, a dedicated team of researchers embarked on a mission that has culminated in the birth of AnyMAL – a paradigm-shifting multimodal language model.
In the dynamic landscape of language comprehension, existing methods and tools often find themselves trailing behind in their endeavors to accommodate the richness of diverse modalities. However, the visionary research collective steering the development of AnyMAL has ingeniously devised a groundbreaking strategy to surmount this challenge. They have ushered forth a colossal Multimodal Language Model (LLM) that seamlessly harmonizes a medley of sensory inputs. AnyMAL transcends the realm of mere language modeling; it encapsulates the potential of artificial intelligence to comprehend and generate language within the intricate tapestry of multimodal contexts.
Picture an interaction with an AI model that fuses sensory cues drawn from the kaleidoscope of the world around us. AnyMAL transforms this vision into reality by enabling inquiries predicated on a shared understanding of the world, facilitated by sensory perceptions encompassing the visual, auditory, and motion realms. Diverging sharply from conventional language models reliant solely on text, AnyMAL possesses the remarkable capability to both process and generate language while embracing the intricate contextual nuances furnished by an array of sensory modalities.
Source: Marktechpost Media Inc.
The methodology underpinning AnyMAL’s development mirrors its awe-inspiring potential. The researchers harnessed open-sourced resources and scalable solutions to mold this multimodal language marvel. A standout innovation lies in the creation of the Multimodal Instruction Tuning dataset (MM-IT) – an intricately curated compendium of annotations tailored specifically for multimodal instruction data. This invaluable dataset played an instrumental role in training AnyMAL, empowering it to decipher and respond to directives that entailed the convergence of multiple sensory inputs.
Among the myriad attributes that elevate AnyMAL to a league of its own is its adeptness at orchestrating multiple modalities with finesse and coherence. It dazzles with exceptional performance in diverse tasks, as substantiated by rigorous comparisons with other vision-language models. Across a spectrum of scenarios, AnyMAL’s capabilities radiate brilliance. In the realm of creative writing, AnyMAL astutely crafts a humorous anecdote in response to the prompt, “Write a joke about it,” deftly connecting it to the image of a nutcracker doll. This feat underscores its prowess in visual recognition, creativity, and humor generation.
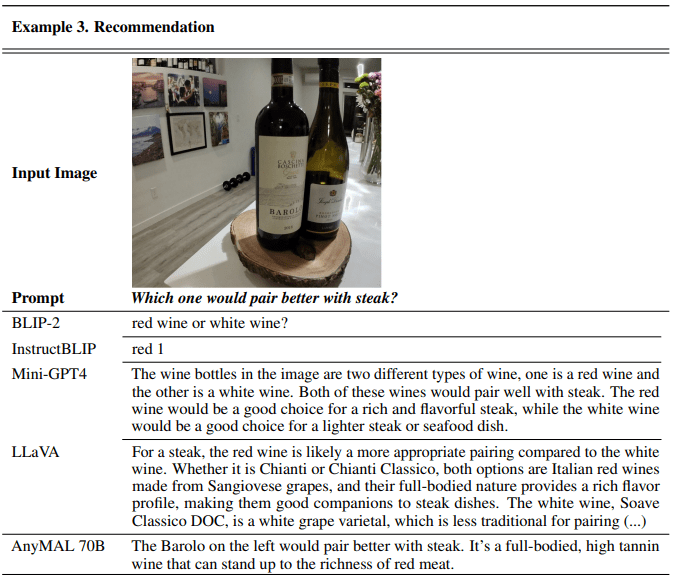
In the realm of practicality, AnyMAL delivers crystal-clear instructions on fixing a flat tire in response to a how-to scenario firmly rooted in its understanding of the image context and its capacity to generate pertinent language. Moreover, when confronted with a query on wine pairing with steak, AnyMAL promptly identifies the ideal wine based on an image of two wine bottles, demonstrating its knack for offering practical recommendations grounded in a visual context.
Venturing into the domain of factual knowledge, AnyMAL adeptly recognizes the Arno River in an image of Florence, Italy, and proceeds to furnish information regarding its length with precision. This testament highlights its prowess in object recognition and factual comprehension.

Source: Marktechpost Media Inc.
Conclusion:
AnyMAL’s introduction marks a significant milestone in the AI market. Its ability to comprehend and generate language across various sensory modalities opens up vast opportunities for businesses. From enhanced customer interaction to content creation and recommendation systems, AnyMAL’s capabilities promise to reshape how industries engage with AI, making it an indispensable tool for the future.