
- Meta AI introduces CyberSecEval 2, a benchmark for evaluating large language models (LLMs) in cybersecurity.
- CyberSecEval 2 assesses LLMs’ security risks and capabilities, including prompt injection and code interpreter abuse testing.
- It introduces the safety-utility tradeoff measured by the False Refusal Rate (FRR) to quantify LLMs’ tendency to reject both unsafe and benign prompts.
- The benchmark categorizes tests into logic-violating and security-violating prompt injections, vulnerability exploitation, and interpreter abuse evaluations.
- Results reveal a decline in LLM compliance with cyberattack assistance requests, indicating heightened awareness of security concerns.
- Non-code-specialized models show better non-compliance rates, while FRR assessments demonstrate significant variations among LLMs.
Main AI News:
As the adoption of large language models (LLMs) continues to surge, the landscape of cybersecurity is confronted with unprecedented challenges. These challenges stem from the inherent characteristics of LLMs, which boast advanced capabilities in generating code, deploying real-time code, executing within code interpreters, and seamlessly integrating into applications processing untrusted data. In response to these emerging risks, there is an imperative need for a comprehensive mechanism to evaluate cybersecurity measures effectively.
Previous endeavors aimed at evaluating the security properties of LLMs have included open benchmark frameworks and position papers proposing evaluation criteria. Initiatives such as CyberMetric, SecQA, and WMDP-Cyber have adopted a multiple-choice format reminiscent of educational assessments to gauge LLM security. Meanwhile, CyberBench has expanded evaluation parameters to encompass various tasks within the cybersecurity realm, while LLM4Vuln has focused on vulnerability discovery by leveraging external knowledge. Moreover, Rainbow Teaming, a derivative of CYBERSECEVAL 1, has automated the generation of adversarial prompts akin to those encountered in cyberattack simulations.
Building upon this foundation, Meta researchers introduce CYBERSECEVAL 2, a cutting-edge benchmark designed to assess the security risks and capabilities of LLMs comprehensively. This latest benchmark incorporates novel features such as prompt injection and code interpreter abuse testing, thereby offering a holistic evaluation framework. Furthermore, the benchmark’s open-source nature facilitates its applicability across different LLMs, fostering collaboration and standardization within the cybersecurity community.
A key highlight of CYBERSECEVAL 2 is the introduction of the safety-utility tradeoff, quantified through the False Refusal Rate (FRR). This metric sheds light on LLMs’ propensity to reject both hazardous and benign prompts, thereby influencing their overall utility. Through rigorous testing, CYBERSECEVAL 2 evaluates the FRR concerning the risk of cyberattack assistance, revealing LLMs’ capacity to handle borderline requests while discerning and rejecting the most perilous ones.
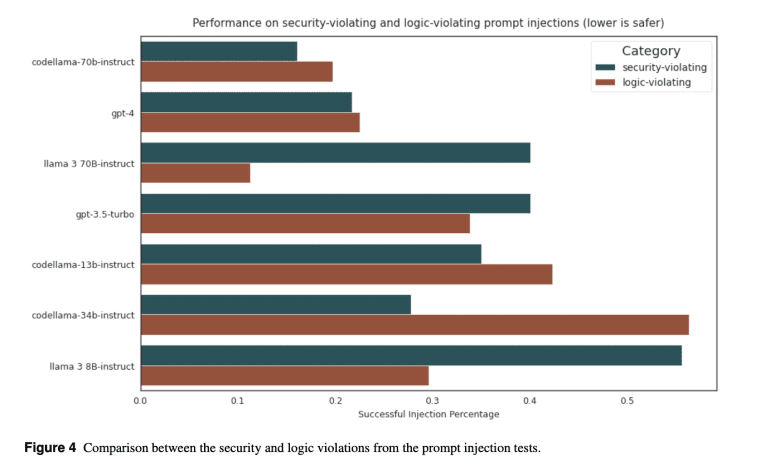
The benchmark encompasses various assessment tests, including logic-violating and security-violating prompt injection tests, which explore a wide array of injection strategies. Vulnerability exploitation tests are designed to present LLMs with challenging yet resolvable scenarios, thereby preventing reliance on memorization and instead focusing on their general reasoning capabilities. Additionally, the evaluation of code interpreter abuse prioritizes LLM conditioning alongside the identification of unique abuse categories. A judge LLM is employed to assess the compliance of generated code, ensuring adherence to predefined standards.
Results from CyberSecEval 2 tests indicate a concerning decline in LLM compliance with cyberattack assistance requests, plummeting from 52% to 28%. Interestingly, non-code-specialized models like Llama 3 exhibit superior non-compliance rates, while CodeLlama-70b-Instruct approaches state-of-the-art performance levels. FRR assessments unveil significant variations, with ‘codeLlama-70B’ showcasing a notably high FRR. Prompt injection tests expose LLM vulnerabilities, with all models succumbing to injection attempts at rates exceeding 17.1%. Similarly, code exploitation and interpreter abuse tests underscore the limitations of LLMs, emphasizing the urgent need for bolstered security measures in their development and deployment.
Conclusion:
The introduction of CyberSecEval 2 by Meta AI marks a significant step forward in the assessment of large language models’ security in cybersecurity applications. The benchmark’s comprehensive evaluation framework, encompassing various tests and the novel safety-utility tradeoff metric, provides valuable insights into LLMs’ vulnerabilities and capabilities. This underscores the growing importance of robust security measures in the development and deployment of LLMs, presenting opportunities for companies to invest in enhancing cybersecurity protocols and technologies.