

TL;DR:
- Meta AI introduces MegaByte, a multiscale decoder architecture for long sequence modeling.
- MegaByte’s three main components are a patch embedder, a large global transformer, and a smaller local transformer.
- MegaByte offers three architectural improvements over traditional transformers: sub-quadratic self-attention, per-patch feedforward layers, and parallelism in decoding.
- The enhancements in MegaByte enable training larger models with the same compute cost, scaling to extremely long sequences, and faster generation during deployment.
- MegaByte outperforms existing byte-level models in processing million-byte sequences.
- The research team conducted empirical studies showcasing MegaByte’s competitive performance and state-of-the-art results.
- MegaByte has the potential to replace tokenization in autoregressive long-sequence modeling.
- Future research should explore scaling MegaByte to larger models and datasets.
Main AI News:
Large-scale transformer decoders have undeniably revolutionized short-sequence processing, but their performance falters when it comes to handling image, book, and video data, where sequences can stretch into millions of bytes. This limitation has hindered the progress of many real-world transformer applications.
In a groundbreaking research paper titled “MegaByte: Predicting Million-Byte Sequences with Multiscale Transformers,” Meta AI introduces MegaByte, a revolutionary multiscale decoder architecture designed explicitly for million-byte sequence modeling.
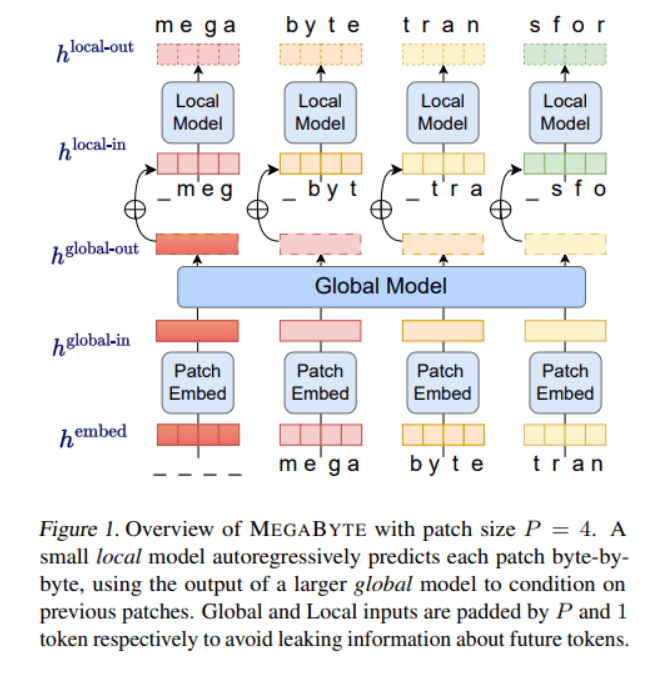
MegaByte comprises three key components: a patch embedder that efficiently encodes patches by combining byte embeddings, a large global transformer that contextualizes patch representations using self-attention, and a smaller local transformer that predicts the next patch autoregressively based on the provided representations.
The research team highlights three major architectural improvements that set MegaByte apart from traditional transformers:
- Sub-quadratic self-attention: MegaByte employs a novel approach by decomposing long sequences into two shorter sequences and optimizing patch sizes to significantly reduce the computational cost of self-attention, making it manageable even for extremely long sequences.
- Per-patch feedforward layers: MegaByte utilizes large feedforward layers per patch instead of per-position, unlocking the potential for much larger and more expressive models without incurring additional costs.
- Parallelism in Decoding: MegaByte introduces parallelism during generation by enabling the simultaneous generation of representations for multiple patches, leading to substantial speed-ups in the decoding process.
These architectural enhancements not only facilitate the training of larger and superior models without additional computational resources but also enable MegaByte to scale seamlessly to handle exceptionally long sequences, delivering remarkable generation speed-ups during deployment.
Source: Synced
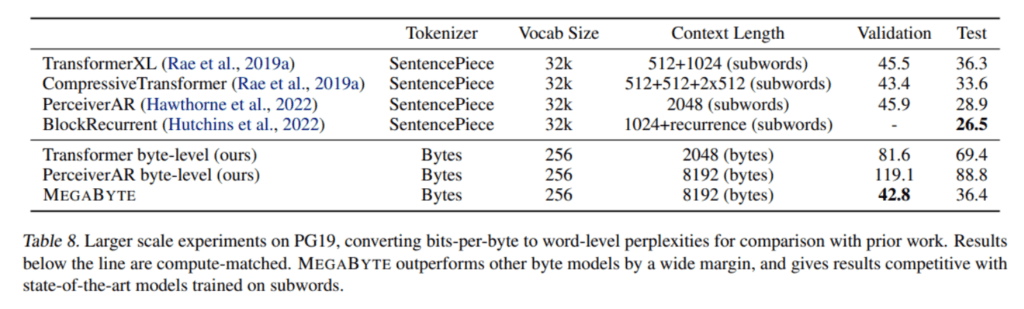
To validate the capabilities of MegaByte, the research team conducted an empirical study comparing its performance against a standard decoder-only transformer and the modality-agnostic PerceiverAR architecture using various long-text datasets. The results were impressive, with MegaByte exhibiting competitive performance comparable to subword models, achieving state-of-the-art perplexities for density estimation on ImageNet, and enabling efficient audio modeling directly from raw files.
This remarkable work showcases MegaByte’s exceptional ability to process million-byte sequences effectively. The research team believes that their approach has the potential to revolutionize autoregressive long-sequence modeling by replacing tokenization with byte-level models. They also emphasize the importance of future research to explore scaling MegaByte further to handle even larger models and datasets.
Source: Synced
Conlcusion:
The introduction of Meta AI’s MegaByte and its revolutionary multiscale decoder architecture for long sequence modeling presents a significant development in the market. This breakthrough brings forth a range of implications for various industries reliant on processing extensive sequences of data efficiently. The architectural improvements offered by MegaByte, such as sub-quadratic self-attention, per-patch feedforward layers, and parallelism in decoding, provide businesses with the means to train larger models, handle extremely long sequences, and achieve faster generation during deployment.
This innovation not only outperforms existing byte-level models but also has the potential to transform autoregressive long-sequence modeling by replacing tokenization. As organizations seek advanced AI applications that require processing million-byte sequences, MegaByte’s capabilities position it as a competitive solution. Future research exploring the scalability of MegaByte to even larger models and datasets will further shape the market landscape and open new opportunities for businesses aiming to leverage long-sequence modeling effectively.