
TL;DR:
- Meta and UC Berkeley introduced “Audio2Photoreal” for creating lifelike avatars.
- Photorealistic avatars now convey natural emotions in real-time conversations.
- The innovative method overcomes the limitations of non-textured meshes.
- Multi-view conversational dataset captures dynamic interpersonal interactions.
- Dual-model approach for facial and body motion synthesis yields realistic, diverse gestures.
- Evaluation proves the model’s effectiveness in motion quality.
- Challenges include limited long-range language understanding and ethical considerations.
Main AI News:
The digital landscape has been reshaped by avatars, taking Snapchat, Instagram, and video games to new heights of user engagement. To elevate this experience further, the collaboration between Meta and BAIR has birthed “Audio2Photoreal,” a pioneering approach that crafts photorealistic avatars, mastering the art of seamless conversation dynamics.
Imagine a telepresent dialogue with a friend, their presence conveyed through a photorealistic 3D model, perfectly mirroring their emotions as they speak. The hurdle? Conquering the limitations of non-textured meshes that fall short in capturing subtle intricacies such as eye movements or smirks can render interactions robotic and eerie. Our research endeavors to bridge this divide, offering a solution to generate photorealistic avatars grounded in the audio of a dyadic conversation.
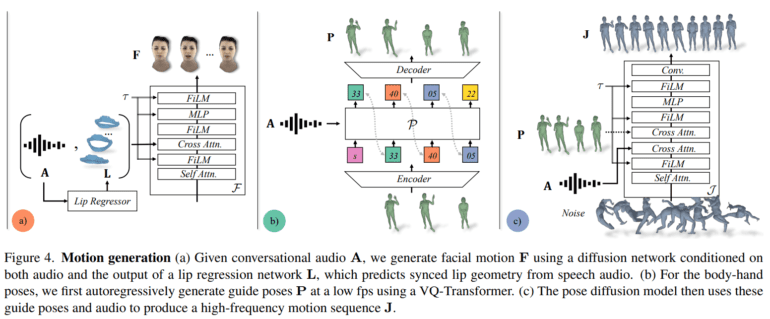
Our methodology revolves around the synthesis of a wide array of high-frequency gestures and expressive facial animations, all intricately synchronized with spoken words. Employing both an autoregressive VQ-based system and a diffusion model for body and hand movements, we have achieved a harmonious balance between frame rate and motion intricacies. The outcome is a system that unveils photorealistic avatars, proficient in conveying intricate facial, bodily, and hand gestures in real-time.
To fortify our research, we have curated a one-of-a-kind multi-view conversational dataset. This dataset stands apart by offering a photorealistic portrayal of unscripted, long-form conversations, delving beyond the usual focus on upper body or facial expressions. It captures the essence of interpersonal exchanges, granting a more holistic comprehension of conversational gestures.
Our system employs a dual-model strategy for facial and body motion synthesis, meticulously addressing the distinct dynamics of these components. The facial motion model, a diffusion model finely tuned to input audio and lip vertices, excels at generating facial intricacies consistent with speech. Conversely, the body motion model relies on an autoregressive audio-conditioned transformer, predicting broad guide poses at 1fps, subsequently refined by the diffusion model to produce an array of diverse yet plausible body movements.
Through rigorous evaluations, our model emerges as a paragon of generating realistic and diverse conversational motions, surpassing various benchmarks. Photorealism, in particular, plays a pivotal role in capturing the subtleties that set human interactions apart, as underlined by our perceptual assessments. The quantitative results underscore our method’s prowess in striking a balance between realism and diversity, outperforming prior endeavors in terms of motion quality.
Nevertheless, our model excels in crafting engaging and credible gestures, but it operates within the confines of short-range audio, posing limitations on its long-range language comprehension capabilities. Furthermore, we remain committed to addressing ethical considerations, ensuring that only consenting participants are featured in our dataset.
Conclusion:
The introduction of “Audio2Photoreal” by Meta and UC Berkeley signifies a significant leap in the realm of photorealistic avatars. This breakthrough technology enhances the user experience by allowing avatars to convey natural emotions and gestures in real-time conversations. This advancement has the potential to reshape various markets, including social media, gaming, virtual communication, and even education. As businesses seek more immersive and engaging ways to connect with their audiences, the demand for such avatars is likely to grow, presenting opportunities for innovation and market expansion. However, addressing the challenges of long-range language understanding and ethical considerations will be crucial for the widespread adoption of this technology.