
TL;DR:
- Researchers from China introduced Meta-Transformer, a unified AI framework for multimodal learning.
- The framework efficiently processes diverse data modalities, such as visual, auditory, and tactile inputs.
- Meta-Transformer’s three key components: modality-specialist, modality-shared encoder, and task-specific heads.
- Extensive multimodal pretraining empowers the framework to excel in various multimodal learning tasks.
- Meta-Transformer outperforms state-of-the-art techniques using only pictures for pretraining.
Main AI News:
In the ever-evolving landscape of artificial intelligence, researchers from China have made a momentous stride with their latest creation, the Meta-Transformer. Drawing inspiration from the human brain’s ability to process information from multiple sensory inputs simultaneously, the Meta-Transformer offers a unified AI framework for multimodal learning, propelling the field into new frontiers.
The Challenge: Bridging the Modality Gap in Deep Learning
As the diverse data modalities of visual, auditory, and tactile signals hold immense potential, constructing a network that can effectively handle such inputs has long been a challenge. Deep learning models designed for one modality often require extensive adjustments to accommodate different data patterns, making the process laborious and time-consuming. For example, images pack significant information redundancy due to tightly packed pixels, while 3D point clouds present difficulties in the description due to their sparse distribution and susceptibility to noise. Audio spectrograms, on the other hand, exhibit non-stationary, time-varying data patterns in the frequency domain. Video data records both spatial and temporal dynamics, comprising a series of frames, while graph data models complex interactions between entities.
The Transformative Solution: Meta-Transformer’s Unified Approach
Meta-Transformer emerges as a game-changer by offering a novel solution to this problem. By leveraging extensive multimodal pretraining on paired data, this groundbreaking framework breaks away from traditional approaches. Unlike prior unified frameworks that focused predominantly on vision and language, Meta-Transformer embraces the challenge of integrating a wide array of modalities.
Three Pillars of Success: Modality-Specialist, Modality-Shared Encoder, and Task-Specific Heads
At the core of Meta-Transformer lie three pivotal components. First, the modality-specialist handles data-to-sequence tokenization, efficiently preparing token sequences with shared manifold spaces from multimodal data. Then, a modality-shared encoder with frozen parameters extracts representations across various modalities, enabling seamless integration of inputs. Finally, task-specific heads for downstream tasks add a touch of personalization to the learning process, further enhancing the framework’s adaptability.
A Remarkable Journey of Success
In rigorous experimentation across 12 diverse modalities, Meta-Transformer has proven its prowess. With superior performance in various multimodal learning tasks, it has outshined state-of-the-art techniques consistently. Notably, Meta-Transformer achieves this remarkable feat while relying solely on pictures from the LAION-2B dataset for pretraining.
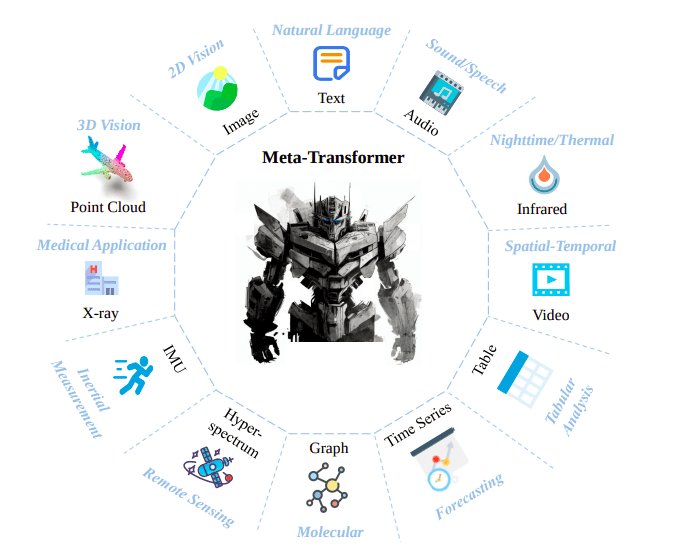
Figure 1: Unlocking the Potential – Meta-Transformer’s Journey Across 12 Modalities
The figure below illustrates how Meta-Transformer boldly explores the potential of transformer-based designs across 12 modalities: pictures, natural language, point clouds, audio spectrograms, videos, infrared, hyperspectral, X-rays, IMUs, tabular, graph, and time-series data. This all-encompassing approach holds the promise of eventually achieving human-level perception across all modalities.
A Collaboration of Brilliance
The brilliance of Meta-Transformer emanates from the collaborative efforts of researchers from the esteemed Chinese University of Hong Kong and Shanghai AI Lab. Their dedication and ingenuity have given rise to a groundbreaking framework that may redefine the future of AI and multimodal learning.
Conclusion:
The introduction of Meta-Transformer signifies a monumental breakthrough in the AI market. Its unified approach to handling diverse data modalities presents significant opportunities for businesses across industries. With its exceptional performance in multimodal learning tasks, Meta-Transformer has the potential to revolutionize how AI systems understand and process information, paving the way for more advanced and sophisticated applications. As businesses and industries embrace this cutting-edge technology, they can harness its power to enhance human-machine interactions, drive innovation, and achieve unprecedented levels of perception and intelligence in their products and services. Embracing Meta-Transformer could be a strategic move for companies seeking to stay at the forefront of AI advancements and gain a competitive edge in the market.