
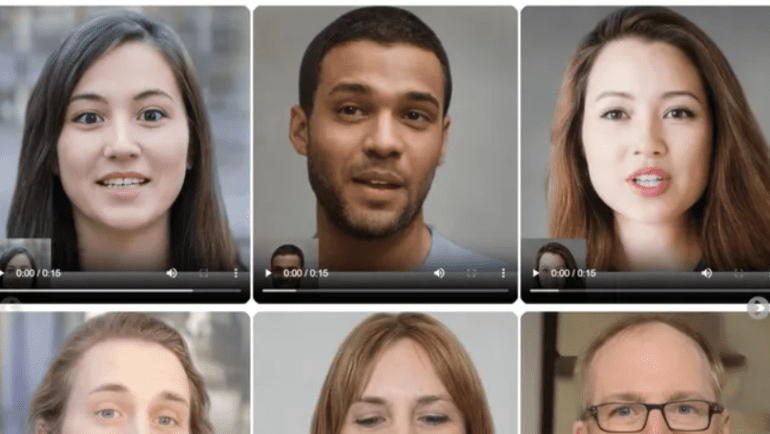
- Microsoft introduces VASA-1 AI system for lifelike avatar creation from a single photo and audio clip.
- VASA-1 goes beyond mouth movement replication, capturing emotions and naturalistic gestures.
- Users can manipulate eye movements, distance perception, and emotional expressions.
- Employs ‘disentanglement’ to control facial dynamics and features independently.
- Adaptable to diverse requests, even those not included in training data.
- Boasts high efficiency, generating high-resolution videos at impressive frame rates.
- Microsoft emphasizes responsible AI considerations in VASA-1’s development.
Main AI News:
Microsoft’s VASA-1 AI video generation system heralds a new era in lifelike avatar creation, transcending traditional boundaries with groundbreaking technology. This innovative system, developed by the tech giant, is revolutionizing the landscape of AI-generated video by seamlessly crafting realistic avatars from a single image coupled with an audio snippet. Named VASA-1, this tool surpasses mere mouth movement replication, delving deep into the realm of emotions and naturalistic gestures.
In addition to accurately mimicking lip sync, VASA-1 empowers users to manipulate eye movements, adjust perceived distance, and fine-tune emotional expressions. It’s not merely a standalone innovation but rather the pioneer of a series of AI advancements, as reported by MSPowerUser. This groundbreaking model excels in conjuring specific facial expressions, synchronizing lip movements with precision, and orchestrating human-like head motions.
VASA-1’s capabilities extend beyond the superficial, offering a nuanced range of emotions and subtleties that promise convincingly authentic results. Its underlying mechanism, dubbed ‘disentanglement,’ mirrors the methodology employed by human 3D animators and modelers, granting unparalleled control over facial dynamics, head positioning, and facial features independently.
This transformative technology holds immense promise, poised to reshape our interactions with digital platforms and interfaces fundamentally. Despite not being trained explicitly on diverse datasets such as artistic imagery, diverse vocalizations, or non-English speech, VASA-1 exhibits remarkable adaptability, seamlessly accommodating a myriad of user requests.
Pioneered by Microsoft researchers, VASA-1 boasts remarkable efficiency, generating high-resolution videos at impressive frame rates. Operating in both offline and online modes, this system achieves a frame rate of 45fps and 40fps, respectively, showcasing its real-time prowess. To delve deeper into VASA-1’s capabilities and functionalities, Microsoft offers a dedicated webpage replete with demonstrations and downloadable resources, emphasizing the importance of responsible AI considerations in its development and deployment.
Conclusion:
Microsoft’s VASA-1 marks a significant leap in AI-generated avatar technology, promising to revolutionize digital interactions. With its ability to create lifelike avatars from minimal input data, manipulate emotions, and deliver high-resolution videos in real-time, VASA-1 opens up new possibilities for diverse applications across various industries, from entertainment and gaming to customer service and virtual communication platforms. Its adaptability and efficiency position it as a formidable player in the market, paving the way for enhanced user experiences and innovative solutions.