
- Microsoft Research and Beihang University have introduced the E5-V framework, revolutionizing multimodal large language models (MLLMs).
- E5-V uses a single-modality approach focused on text pairs, simplifying training and reducing costs.
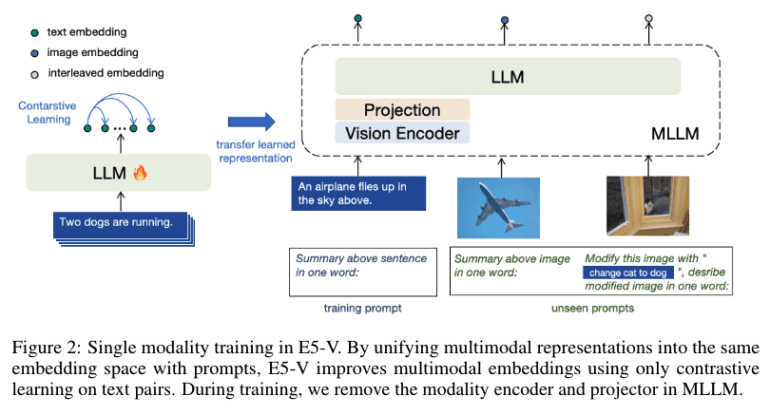
- The framework features a novel prompt-based representation technique, unifying multimodal data into a single embedding space.
- E5-V shows significant improvements in performance benchmarks, including a 12.2% gain on Flickr30K and a 15.0% gain on COCO in zero-shot image retrieval.
- In composed image retrieval, E5-V outperforms the leading method iSEARLE-XL by up to 10.07% in Recall@5.
- Experimental results confirm E5-V’s effectiveness, with competitive scores on datasets like Flickr30K and CIRR, showing superior performance over existing models.
Main AI News:
Microsoft Research, in collaboration with Beihang University, has introduced E5-V, a revolutionary AI framework designed to advance multimodal large language models (MLLMs). This new development addresses key challenges in integrating and representing diverse data types, such as text and images, and marks a significant step forward in AI research and application.
Multimodal learning, which combines verbal and visual data, has been a focus of contemporary AI research due to its potential to create more nuanced and accurate representations of complex inputs. Traditional MLLMs, such as CLIP, BLIP, and LLaVA, have attempted to bridge the gap between text and images by using separate encoders and extensive multimodal datasets. However, these approaches often lead to inefficient data integration and high training costs, as well as difficulties in achieving comprehensive language understanding and handling complex visual-linguistic tasks.
The E5-V framework represents a paradigm shift by employing a single-modality training approach on text pairs. This innovative method drastically reduces the need for multimodal data collection, which has been a significant barrier in developing effective MLLMs. By focusing solely on text pairs, E5-V simplifies the training process and cuts associated costs, addressing the inefficiencies of previous methods.
A core feature of E5-V is its novel prompt-based representation technique. This approach unifies multimodal embeddings into a single space, allowing the model to handle a wide range of data types with greater ease. By instructing MLLMs to represent multimodal inputs as textual data, E5-V effectively bridges the modality gap, improving the model’s ability to perform tasks such as image retrieval and composed image retrieval. This unification enhances the robustness and versatility of multimodal representations, enabling more accurate and comprehensive understanding of complex inputs.
E5-V has demonstrated In conclusion: Microsoft’s introduction of the E5-V framework represents a major advancement in AI technology. By offering a more efficient and cost-effective solution for multimodal learning through single-modality training, E5-V is poised to influence the market significantly. It reduces reliance on complex and expensive multimodal datasets, potentially lowering development costs and accelerating innovation in AI applications. This could set a new standard for future AI systems, driving broader adoption and pushing the boundaries of what is possible in multimodal integration.impressive results across a variety of benchmarks and tasks. In zero-shot image retrieval, the framework has outperformed established models like CLIP ViT-L, achieving a 12.2% improvement on the Flickr30K dataset and a 15.0% improvement on COCO, based on Recall@1 metrics. In composed image retrieval, E5-V has surpassed the state-of-the-art method iSEARLE-XL by 8.50% on Recall@1 and 10.07% on Recall@5 on the CIRR dataset. These results highlight E5-V’s superior ability to integrate and represent multimodal data effectively.
Further validation of E5-V’s capabilities comes from its performance in extensive experiments. On the Flickr30K and COCO datasets, E5-V achieved competitive results, including a Recall@10 of 98.7% on Flickr30K, outperforming models that rely on image-text pairs. Additionally, in composed image retrieval tasks, E5-V showed remarkable improvements with Recall@10 scores of 75.88% on CIRR and 53.78% on FashionIQ, significantly higher than existing baseline models. These findings emphasize E5-V’s efficiency in representing multimodal information without requiring additional fine-tuning or complex training data.
Conclusion:
Microsoft’s introduction of the E5-V framework represents a major advancement in AI technology. By offering a more efficient and cost-effective solution for multimodal learning through single-modality training, E5-V is poised to influence the market significantly. It reduces reliance on complex and expensive multimodal datasets, potentially lowering development costs and accelerating innovation in AI applications. This could set a new standard for future AI systems, driving broader adoption and pushing the boundaries of what is possible in multimodal integration.