
TL;DR:
- Microsoft introduces an FP8 mixed-precision training framework for large language models (LLMs).
- FP8 offers faster processing, reduced memory usage, and lower communication costs compared to existing precision levels.
- Researchers address challenges like data overflow and quantization errors with automatic scaling and precision decoupling.
- Experimental results show significant reductions in memory usage and communication overhead with FP8 training.
- FP8 adoption can lead to substantial cost savings, especially as LLMs scale.
- The framework supports instruction customization and reinforcement learning, boosting training speed.
- AlpacaFarm, an RLHF framework, sees significant benefits with FP8.
- Microsoft’s contributions set a new standard for low-precision training systems, promising efficiency gains in the market.
Main AI News:
In the ever-evolving landscape of artificial intelligence, large language models have risen to prominence, demonstrating unprecedented prowess in language generation and comprehension. Their impact transcends linguistic domains, extending into the realms of logic, mathematics, physics, and more. However, the path to achieving these extraordinary capabilities is riddled with a substantial price tag. Training colossal language models, such as the 540B variant, demands a staggering 6,144 TPUv4 chips for Project PaLM, while GPT-3 175B consumes several thousand petaflop/s-days of computation during pre-training. These staggering resource requirements underscore the urgency of reducing the costs associated with training large language models, especially as we aspire to usher in the next generation of highly intelligent AI models.
Enter the world of low-precision training, a promising avenue that offers accelerated processing, minimal memory usage, and streamlined communication overhead. Presently, most training systems, including Megatron-LM, MetaSeq, and Colossal-AI, default to using either FP16/BF16 mixed-precision or FP32 full-precision for training large language models. While these precision levels are indispensable for preserving accuracy in massive models, they come at a significant computational cost.
A glimmer of hope emerges with the introduction of FP8, the next-generation datatype for low-precision representation, coinciding with the debut of the Nvidia H100 GPU. FP8 stands poised to unleash a revolution, potentially delivering a two-fold increase in speed, coupled with memory cost reductions of 50% to 75% and communication savings in the same range. These promising outcomes hold immense potential for scaling up the next wave of foundational language models. However, FP8 still requires further development and occasional intervention to reach its full potential.
The Nvidia Transformer Engine, currently the sole framework compatible with FP8, primarily utilizes this precision for GEMM (General Matrix Multiply) computations, while maintaining master weights and gradients with extreme precision, such as FP16 or FP32. Consequently, the overall performance gains, memory savings, and communication cost reductions remain somewhat constrained, preventing FP8 from fully shining.
In response to this challenge, a team of researchers from Microsoft Azure and Microsoft Research has unveiled a highly efficient FP8 mixed-precision framework tailored specifically for large language model training. The central concept behind their innovation revolves around harnessing low-precision FP8 for computation, storage, and communication throughout the training process of massive models. This strategic shift promises to significantly alleviate the system requirements compared to earlier frameworks.
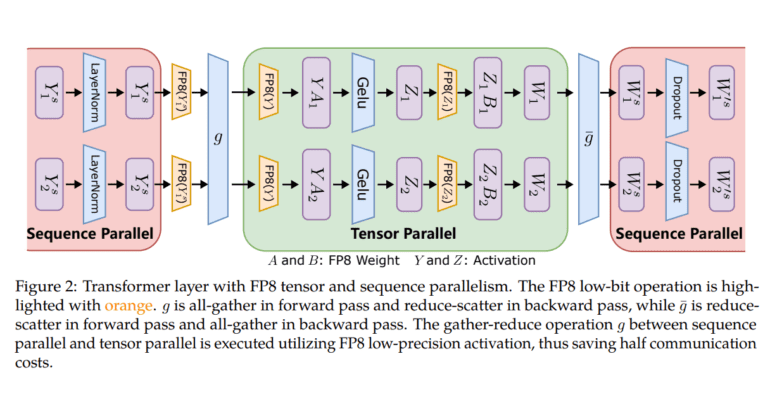
To delve deeper into their approach, they have introduced three optimization stages that leverage FP8 for distributed and mixed-precision training. As one progresses through these tiers, a higher degree of FP8 integration becomes apparent, suggesting a more significant impact on the LLM training process. Additionally, their system introduces FP8 low-bit parallelism, encompassing tensor, pipeline, and sequence parallelism, thereby enabling large-scale training scenarios, such as GPT-175B trained on thousands of GPUs, effectively ushering in the era of next-generation low-precision parallel training.
However, working with FP8 presents its own set of challenges. These hurdles include issues like data overflow or underflow, as well as quantization errors stemming from the reduced accuracy and narrower dynamic range of FP8 data formats. Throughout the training journey, these challenges can lead to persistent divergences and numerical instability.
To address these intricacies, the researchers propose two crucial methods: automatic scaling and precision decoupling. The former involves precision reduction for components that are not sensitive to precision, coupled with dynamic adjustments of tensor scaling factors to ensure gradient values remain within the FP8 representation range. This safeguards against underflow and overflow incidents during all-reduce communication, ensuring a smoother training process.
The researchers have put their FP8 low-precision framework to the test, employing it in GPT-style model training, including supervised fine-tuning and pre-training. In comparison to the widely adopted BF16 mixed-precision approach, their experimental results showcase substantial benefits, including a 27% to 42% reduction in real memory usage and a remarkable 63% to 65% decrease in weight gradient communication overhead. Astonishingly, these gains come without any adjustments to hyper-parameters, such as learning rates and weight decay. During the GPT-175B model’s training, their FP8 mixed-precision framework not only conserves 21% of the memory on the H100 GPU platform but also shaves off 17% of training time compared to TE (Transformer Engine).
Furthermore, as models continue to scale, as exemplified in Figure 1, the cost savings attained through low-precision FP8 training are poised to soar. In a bid to align pre-trained LLMs more closely with specific tasks and user preferences, the researchers leverage FP8 mixed precision for instruction customization and reinforcement learning with human input. By tapping into publicly available user-generated instruction-following data, they achieve a remarkable 27% boost in training speed, all while maintaining performance parity with models relying on the higher-precision BF16 standard in evaluations such as AlpacaEval and MT-Bench benchmarks. Moreover, FP8 mixed-precision exhibits significant promise in RLHF (Reinforcement Learning from Human Feedback), a demanding process that involves training numerous models concurrently.
The widely-used RLHF framework, AlpacaFarm, stands to benefit greatly from FP8 adoption during training, with a potential 46% reduction in model weights and a staggering 62% reduction in memory usage for optimizer states. These compelling results underscore the adaptability and versatility of the FP8 low-precision training architecture.
In summary, the contributions made by the Microsoft Research team to advance FP8 low-precision training for LLMs in the future generation are nothing short of groundbreaking. Their fresh framework for mixed-precision training in FP8, designed for easy adoption and gradual integration of 8-bit weights, gradients, optimizer, and distributed training, sets a new industry standard. Additionally, they offer a Pytorch implementation that simplifies 8-bit low-precision training with just a few lines of code.
To complement this framework, they present a new line of FP8-trained GPT-style models, showcasing the potential of FP8 across a wide range of model sizes, from 7B to a staggering 175B parameters. These models support FP8 across popular parallel computing paradigms, thereby paving the way for training massive foundational models with unprecedented efficiency. Their FP8 GPT training codebase, built upon the Megatron-LM framework, is now available to the public, setting the stage for a new era of low-precision training systems designed for the colossal foundation models of the future.
Conclusion:
Microsoft’s FP8 mixed-precision training framework represents a game-changing development in the market for large language models. By significantly reducing training costs, enhancing performance, and supporting the scaling of models, this innovation is poised to drive efficiency and cost-effectiveness in AI research and applications. Companies and organizations invested in AI development should take note of these advancements to stay competitive in a rapidly evolving landscape.