
TL;DR:
- Microsoft Research introduces AdaptLLM, a domain-adaptive pretraining method.
- Three strategies were explored for specialized models: building from scratch, refining pre-existing programs, and domain-adaptive pretraining.
- Domain-adaptive pretraining involves training LLMs on extensive domain-specific text datasets.
- Experiments in biology, finance, and law reveal a trade-off between domain knowledge and prompting ability.
- Microsoft’s solution: Transforming raw corpora into reading comprehension texts to enhance prompting performance.
- AdaptLLM blends domain knowledge and prompting capability, showing improved performance.
- Implications for AI: AdaptLLM balances knowledge acquisition and effective prompting, opening possibilities in various industries.
Main AI News:
In a strategic move aimed at surmounting the challenges that have long plagued large language models (LLMs) in their quest to generate and comprehend specialized text, Microsoft Research has introduced a groundbreaking innovation: AdaptLLM, as detailed in their recent study paper. This novel approach, which revolves around domain-adaptive pretraining, stands out for its remarkable cost-effectiveness and its unparalleled ability to elevate the performance of LLMs in tasks that are intrinsically tied to specific domains.
Strategies Explored for Specialized Models
Venturing into the realm of specialization, Microsoft’s dedicated team of researchers meticulously examined three primary strategies. The first strategy involved constructing a program from scratch—an intricate process demanding substantial resources. Unfortunately, this method proved to be laborious and inefficient. The second approach aimed to enhance pre-existing programs through supplementary training, but it delivered inconsistent outcomes across diverse tasks.
The third and ultimately chosen strategy harnessed the wealth of pre-existing knowledge within a given field to educate the program. This innovative approach, known as domain-adaptive pretraining, entailed training an LLM on a vast text dataset specific to a particular domain. This immersive training approach empowered the model to assimilate the critical vocabulary and fundamental concepts inherent to that domain.
Pioneering Experiments Across Varied Domains
In a series of pioneering experiments spanning the domains of biology, finance, and law, Microsoft’s research team unearthed profound insights into the impact of additional training on raw corpora. For those unacquainted with the term, raw corpora refer to vast collections of text or speech devoid of any linguistic processing or annotations. These unprocessed datasets serve as the foundational data source for natural language processing tasks, including text analysis, machine translation, and speech recognition. Raw corpora can be sourced from diverse outlets such as books, newspapers, websites, social media, transcripts, and recordings.
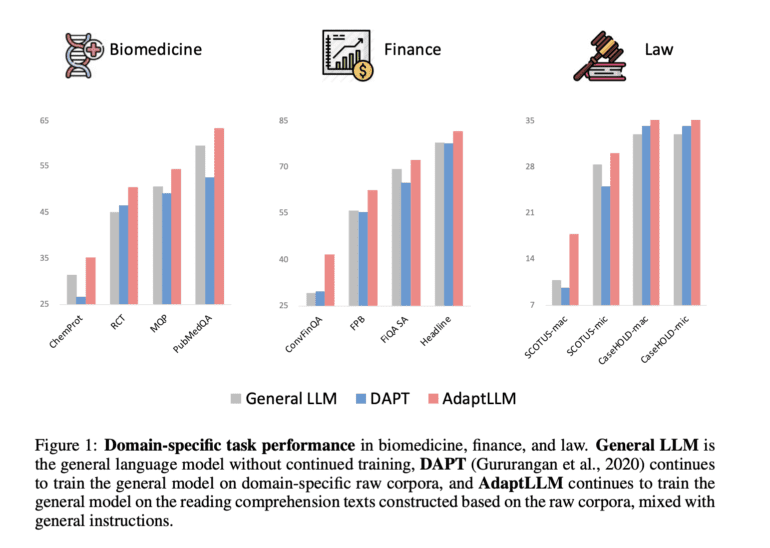
Microsoft’s research findings unveiled a notable trade-off: while domain-adaptive pretraining with raw corpora enriched the LLM’s domain knowledge, it concurrently diminished its ability to respond effectively to prompts.
A Creative Solution: Transforming Raw Corpora into Reading Comprehension Texts
In response to this challenge, the research team devised a simple yet remarkably effective technique. They transformed extensive raw corpora into reading comprehension texts, a move that substantially bolstered prompting performance. This innovative approach involved incorporating various tasks related to the subject matter of each raw text. By doing so, the model retained its capacity to answer queries in natural language, all while leveraging the context provided by the original text.
Blending Domain Knowledge with Prompting Proficiency
The culmination of this research endeavor is none other than AdaptLLM, a model that has demonstrated enhanced performance across an array of domain-specific tasks. Trained through domain-adaptive pretraining on reading comprehension texts, AdaptLLM beautifully amalgamates domain knowledge acquisition with the preservation of prompting capability. Looking forward, Microsoft’s researchers envision the expansion of this methodology, potentially giving rise to a versatile, large language model capable of accommodating a wide spectrum of tasks across diverse domains.
Implications for the Future of AI
The introduction of AdaptLLM heralds a significant stride forward in the evolution of artificial intelligence. By striking a delicate balance between acquiring domain-specific knowledge and maintaining the ability to prompt effectively, AdaptLLM opens up a world of possibilities for enhanced applications across various sectors, ranging from biomedicine to finance and law. This innovation exemplifies Microsoft’s commitment to pushing the boundaries of AI and delivering solutions that cater to the evolving needs of specialized learning.
Conclusion:
Microsoft’s AdaptLLM represents a significant advancement in AI, addressing the unique challenges of domain-specific learning. By achieving a balance between domain knowledge and prompting efficiency, it paves the way for enhanced applications across industries, promising a brighter future for specialized AI solutions in the market.