
TL;DR:
- Microsoft introduces NaturalSpeech 2, a TTS system leveraging latent diffusion models for powerful zero-shot voice synthesis and enhanced expressive prosodies.
- The goal of TTS is to generate high-quality, diverse speech that resembles real human speech, and NaturalSpeech 2 excels in achieving this.
- The system employs continuous vectors instead of discrete tokens, resulting in improved speech reconstruction accuracy at a granular level.
- NaturalSpeech 2 replaces autoregressive models with diffusion ones, enhancing its zero-shot capacity for voice synthesis.
- Speech prompting mechanisms enable in-context learning, further improving zero-shot capabilities.
- The system outperforms previous TTS models, generating natural speech in zero-shot scenarios with various speaker identities, prosodies, and styles, including singing voices.
- Microsoft aims to explore consistency models for better diffusion model performance and train speaking and singing voices together for more potent mixed capabilities.
Main AI News:
In the ever-evolving realm of text-to-speech (TTS) technology, achieving lifelike speech that resonates with real human intonation has been a long-standing goal. Factors like speaker identities encompassing gender, accent, and timbre, alongside diverse speaking and singing styles, play a pivotal role in delivering the richness of human speech. Advancements in neural networks and deep learning have undoubtedly improved the intelligibility and naturalness of TTS systems, with some, like NaturalSpeech, even reaching human-level voice quality on single-speaker recording-studio benchmarks.
However, a hurdle lies in the lack of diversity within the data used for training. Previous datasets primarily limited to a few speakers in controlled studio environments failed to capture the vast array of speaker identities, prosodies, and speech styles present in the real world. This limitation is now being addressed by leveraging cutting-edge few-shot or zero-shot technologies. By training TTS models on large corpora, these models can discern the nuances among different speakers and speech styles and subsequently generalize to an infinite range of unseen scenarios.
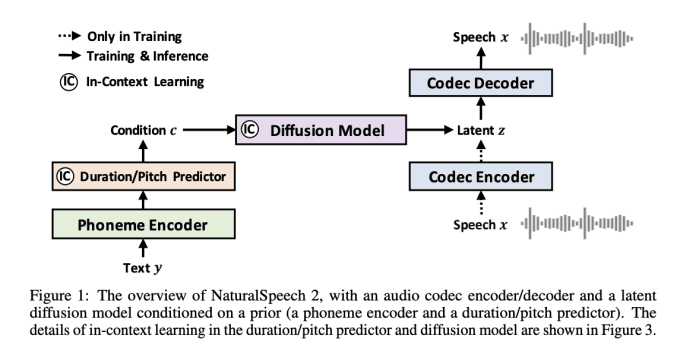
Enter NaturalSpeech 2, Microsoft’s latest breakthrough in TTS systems. This revolutionary technology adopts latent diffusion models, which endows it with expressive prosody, remarkable resilience, and, crucially, robust zero-shot capabilities for voice synthesis. The researchers’ journey commenced by training a neural audio codec, employing a codec encoder to transform speech waveforms into latent vectors and a codec decoder to restore the original waveforms. Building on that foundation, previous vectors from a phoneme encoder, duration predictor, and pitch predictor are combined with a diffusion model to construct these latent vectors.
The research paper delves into various design decisions pivotal to this groundbreaking achievement:
• Departing from the conventional approach of using numerous residual quantizers to ensure the quality of the neural codec’s speech reconstruction, the team embraced continuous vectors instead of discrete tokens. This innovation shortened the sequence, allowing for more accurate speech reconstruction at a granular level.
• Embracing diffusion models over autoregressive ones.
• Introducing speech prompting mechanisms that promote in-context learning within the diffusion model and pitch/duration predictors. This enhancement significantly improves the zero-shot capacity by aligning the diffusion models with the characteristics of the speech prompt.
• A key differentiator of NaturalSpeech 2 lies in its reliability and stability, as it requires just a single acoustic model (the diffusion model) instead of a two-stage token prediction. Consequently, it can seamlessly apply its duration/pitch prediction and non-autoregressive generation to diverse styles beyond speech, such as singing voices.
The efficacy of these architectural choices is demonstrated through extensive training in NaturalSpeech 2, which boasts a staggering 400M model parameters and 44K hours of speech data. The results are awe-inspiring as the system deftly generates speech in zero-shot scenarios with varying speaker identities, prosody, and styles, including singing. Notably, NaturalSpeech 2 surpasses its predecessors and other powerful TTS systems in experiments, delivering remarkably natural speech in zero-shot conditions. It impressively aligns prosody with the speech prompt and ground-truth speech, while also achieving comparable or even superior naturalness (in terms of CMOS) when compared to the ground-truth speech on LibriTTS and VCTK test sets. An exciting revelation is NaturalSpeech 2’s ability to generate singing voices in a novel timbre with only a short singing prompt or, intriguingly, with just a speech prompt, unlocking the true potential of zero-shot singing synthesis.
Looking ahead, the Microsoft AI Team is committed to exploring even more effective methods, including consistency models, to accelerate the diffusion model’s performance. Additionally, their future endeavors will focus on widespread training encompassing both speaking and singing voices, enabling even more potent mixed speaking/singing capabilities. With NaturalSpeech 2, Microsoft has undoubtedly set a new benchmark in TTS technology, paving the way for more immersive and expressive voice synthesis in the years to come.
Conclusion:
Microsoft’s NaturalSpeech 2 represents a significant advancement in the text-to-speech market. By harnessing latent diffusion models and continuous vectors, the system achieves exceptional voice synthesis quality, making it a top choice for industries reliant on natural and expressive speech generation. Its zero-shot capabilities and versatility in accommodating diverse styles further solidify its position as a game-changer in the TTS industry. Businesses in sectors like virtual assistants, entertainment, education, and accessibility are likely to benefit greatly from this cutting-edge technology, offering more engaging and personalized user experiences. As competition intensifies, companies will need to stay abreast of such innovations to remain competitive in an ever-evolving market.