
TL;DR:
- Microsoft introduces LLaVA-Med, an efficient language and vision assistant revolutionizing biomedical inquiry.
- LLaVA-Med combines language and vision capabilities to respond to free-form inquiries about biomedical images.
- The model is trained using a novel curriculum learning approach and a large-scale biomedical figure-caption dataset.
- LLaVA-Med achieves state-of-the-art performance on benchmark biomedical visual question-answering datasets.
- The research team’s key contributions include multi-modal medical training compliance statistics, LLaVA-Med model development, and open-source initiatives for further study in biomedical multi-modal learning.
Main AI News:
In the world of conversational generative AI, there is immense potential to assist medical professionals. However, the focus thus far has primarily been on text-based interactions. While advancements in multi-modal conversational AI have been significant, thanks to the abundance of image-text pairings available, there is still room for improvement when it comes to interpreting and discussing biological images.
Recognizing this, Microsoft’s research team has put forth a low-effort method to train a vision-language conversational assistant to respond to free-form inquiries about biomedical images. Their proposed approach involves a novel curriculum learning strategy that fine-tunes a large general-domain vision-language model using a vast biomedical figure-caption dataset extracted from PubMed Central, in conjunction with the power of GPT-4 to self-instruct open-ended instruction-following data from the captions.
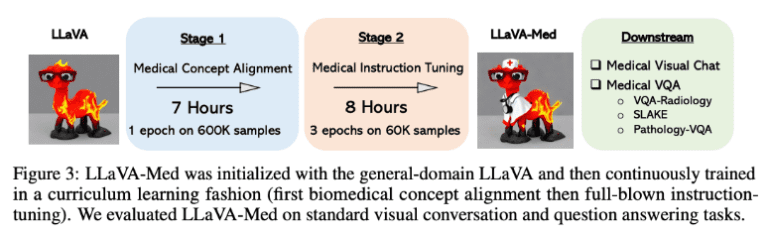
The process by which the model learns mimics the gradual accumulation of biological knowledge by a layman. Initially, the model aligns itself with biomedical vocabulary using the provided figure-caption pairs. Then, it progresses to master open-ended conversational semantics using GPT-4’s generated instruction-following data. Astonishingly, in under 15 hours, using eight A100s, researchers can train the Large Language and Vision Assistant for BioMedicine (LLaVA-Med).
Equipped with its multi-modal conversational capacity and ability to comprehend free-form instructions, LLaVA-Med is primed to provide answers to questions pertaining to biological images. After fine-tuning, LLaVA-Med achieves state-of-the-art performance on three benchmark biomedical visual question-answering datasets. To advance multi-modal research in biomedicine, the team plans to make both the data on human directions-following capabilities and the LLaVA-Med model publicly accessible.
Let’s delve into the key contributions made by the team:
- Multi-modal medical training compliance statistics: To generate diverse instances comprising image, instruction, and output, the team meticulously selected biomedical picture-text pairs from PMC-15M. Leveraging GPT-4, they generated instructions solely from the textual information, resulting in a unique data creation pipeline.
- LLaVA-Med: The team utilized the self-generated biomedical multi-modal instruction-following dataset to introduce a novel curriculum learning method. This method allows LLaVA to adapt and excel in the biomedical domain.
- Open-source initiative: In order to encourage further exploration in the realm of biomedical multi-modal learning, the team plans to make the biomedical multi-modal instruction-following dataset, as well as the software for data generation and model training, publicly available.
To evaluate the effectiveness of LLaVA-Med and the accuracy of the multi-modal biomedical instruction-following data, the team conducted investigations in two different contexts:
- Evaluating LLaVA-Med as a general-purpose biomedical visual chatbot: The team established a novel data generation pipeline that involved sampling 600K image-text pairs from PMC-15M. By leveraging GPT-4, they curated diverse instruction-following data and aligned it with the model, effectively addressing the scarcity of multi-modal biomedical datasets for training an instruction-following assistant.
- Benchmark comparisons: The team introduced a new training method for LLaVA-Med’s curriculum. They began by training the LLaVA multi-modal conversation model in broad domains and gradually transitioned to the biomedical field. This training process encompassed two phases: aligning word embeddings with relevant image attributes of innovative biological visual concepts and fine-tuning the model based on biomedical language-image instructions. The result was an impressive zero-shot task transfer capability and enhanced user interaction.
In summary, Microsoft’s research team presents LLaVA-Med, a large language and vision model specifically designed for the biomedical field. Their approach involves a self-instruct strategy, employing language-only GPT-4 and external knowledge to construct a data curation pipeline. The model has then trained on a high-quality biomedical language-image instruction-following dataset.
After fine-tuning, LLaVA-Med surpasses previous state-of-the-art supervised methods on three visual question-answering datasets, showcasing its remarkable conversational abilities coupled with domain knowledge. While LLaVA-Med represents a significant advancement, the team acknowledges the presence of hallucinations and a lack of depth of reasoning that can affect many similar models. As future initiatives unfold, their focus will be on enhancing reliability and ensuring high-quality performance.
Conclusion:
The introduction of LLaVA-Med by Microsoft signifies a significant advancement in the field of biomedical inquiry. By leveraging advanced multimodal conversations, LLaVA-Med empowers medical professionals with the ability to engage with and interpret biological images effectively. The model’s state-of-the-art performance on benchmark datasets establishes it as a valuable tool for enhancing biomedical research and decision-making processes.
As LLaVA-Med continues to evolve and address its limitations, it holds great potential to reshape the market by providing innovative solutions and driving progress in the biomedical industry. Businesses operating in this space should take note of the transformative impact LLaVA-Med can have on biomedical conversations and consider its integration into their workflows to stay at the forefront of advancements in the field.