
TL;DR:
- Microsoft introduces Pareto optimal self-supervision framework to address hallucination in large language models (LLMs).
- The framework utilizes programmatic supervision to calibrate and rectify errors in LLMs, reducing the need for manual intervention.
- LLM calibration involves designing a risk indicator function to estimate the true probability of hallucination.
- Self-supervision is used to derive the risk indicator function, leveraging unlabeled training examples.
- The proposed harmonizer model aligns with both LLM responses and specified supervision functions, ensuring high-quality calibration.
- Dynamic prompting strategies, such as dynamic self-examination and dynamic self-supervision, facilitate error correction for more confident LLM responses.
- Empirical study demonstrates consistent high error calibration rates, boosting the performance of GPT-3 and GPT-4 models with additional human-labeled training data.
Main AI News:
In the realm of natural language processing and comprehension, large language models (LLMs) have proven to be exceptionally powerful. Nonetheless, the persistent challenge of hallucination continues to cast a shadow over their real-world applications, where utmost precision and dependability are paramount.
To tackle this predicament head-on, a team of researchers from Microsoft has introduced a pioneering solution in their recent paper titled “Automatic Calibration and Error Correction for Large Language Models via Pareto Optimal Self-Supervision.” This paper unveils a revolutionary and versatile framework called Pareto optimal self-supervision, which leverages programmatic supervision to rectify and fine-tune the inherent errors within LLMs, eliminating the need for additional manual intervention.
At the core, the team approaches the problem through the lens of a prompt-based LLM workflow. In this workflow, given a specific prompt setting and input text, the LLM generates a textual response. This response is then projected onto the desired output space using an operator, while simultaneously offering an abstain option to determine the clarity or uncertainty of the generated text. However, if the model confidently asserts an answer that turns out to be incorrect, the challenge of hallucination persists.
The primary objective of LLM calibration is to devise a risk indicator function capable of estimating the true probability of hallucination. In this endeavor, the researchers employ self-supervision to derive the risk indicator function, leveraging unlabeled training examples where ground truth outputs are completely unavailable.
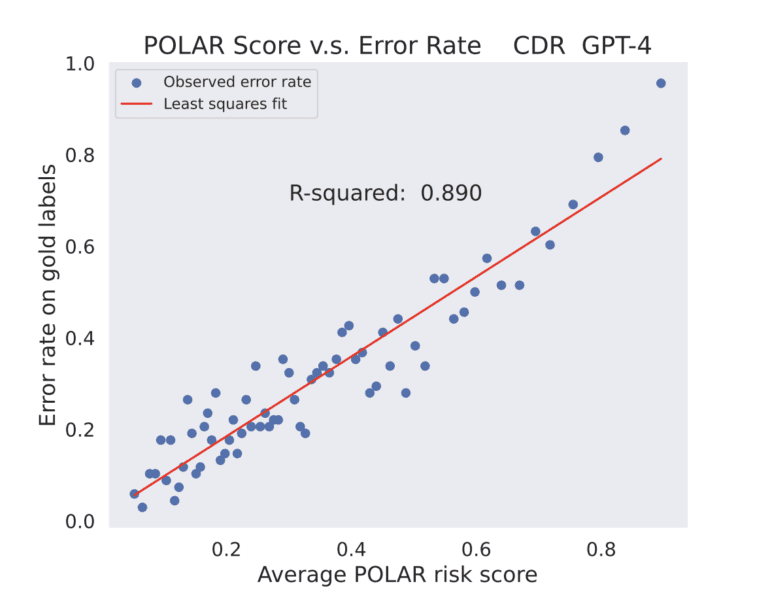
A pivotal component of the proposed Pareto optimal learning approach is the harmonizer model, designed to align seamlessly within the semantic space while adhering to both the LLM response and the specified supervision function. To ensure optimal calibration quality from the harmonizer model, the team puts forth two dynamic prompting strategies: dynamic self-examination and dynamic self-supervision. These strategies leverage POLAR scores to facilitate error correction, leading to more confident and accurate LLM responses. In an empirical study, the team applies Pareto optimal learning to four demanding natural language processing datasets: CDR, ChemProt, SemEval, and SMS. The outcomes are remarkable, demonstrating consistent high real error calibration rates for LLMs and boosting the performance of state-of-the-art (SOTA) models like GPT-3 and GPT-4 by incorporating additional human-labeled training data.
Conclusion:
Microsoft’s Pareto Optimal Self-Supervision framework represents a significant advancement in the field of language models. By effectively addressing the challenge of hallucination and improving the accuracy and reliability of LLMs, this innovation has the potential to reshape the market for natural language processing. With enhanced calibration capabilities and a reduction in manual intervention, businesses can leverage LLMs with greater confidence, leading to improved performance in various real-world applications. This framework sets a new standard for language model development and paves the way for future advancements in the industry.