
- Evaluating conversational AI systems, such as GitHub Copilot Chat, is complex due to reliance on language models and chat-based interfaces.
- Current metrics fall short for domain-specific dialogues, necessitating new evaluation methods.
- RUBICON, developed by Microsoft, addresses these issues by generating and selecting high-quality, task-aware rubrics for evaluation.
- It improves on existing methods like SPUR by incorporating domain-specific signals and Gricean maxims.
- Tested on 100 C# debugging assistant conversations, RUBICON demonstrated superior precision and effectiveness in predicting conversation quality.
- Traditional metrics like BLEU and Perplexity are inadequate for long-form conversations, especially in large language models.
- RUBICON evaluates conversation quality by developing rubrics for Satisfaction and Dissatisfaction, using a 5-point Likert scale normalized to [0, 10].
- The technique has shown effectiveness in real-world scenarios, outperforming other rubric sets and demonstrating practical value.
Main AI News:
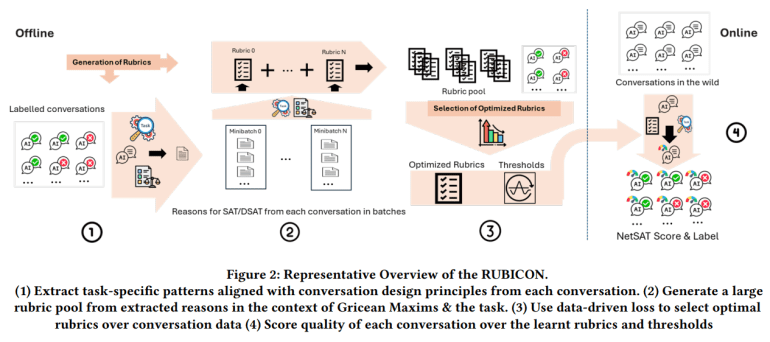
Evaluating conversational AI systems, such as GitHub Copilot Chat, presents significant challenges due to their dependence on language models and chat-based frameworks. Current metrics fall short for domain-specific conversations, complicating the assessment of these tools’ effectiveness. While SPUR employs large language models to gauge user satisfaction, it often overlooks domain-specific details. The study introduces RUBICON, a machine learning technique that generates and selects high-quality, task-aware rubrics for evaluating task-oriented AI assistants, focusing on context and task progression to enhance evaluation precision.
RUBICON, developed by Microsoft researchers, advances the evaluation of domain-specific Human-AI interactions through large language models. It generates candidate rubrics to evaluate conversation quality and identifies the most effective ones. By incorporating domain-specific cues and Gricean maxims, RUBICON improves on SPUR, creating and refining a set of rubrics through iterative evaluation. Tested on 100 conversations between developers and a chat-based C# debugging assistant, RUBICON, leveraging GPT-4 for rubric generation, demonstrated superior precision in predicting conversation quality compared to other rubric sets, validated through ablation studies.
Natural language conversations are pivotal in AI applications, yet traditional metrics like BLEU and Perplexity fall short for evaluating extensive dialogues, particularly in large language models. Although user satisfaction has been a traditional metric, manual analysis is costly and invasive. Recent methods use language models for quality assessment through natural language assertions, addressing engagement and user experience themes. While SPUR generates rubrics for open-domain conversations, domain-specific contexts remain a challenge. This study advocates a comprehensive approach, merging user expectations and interaction progress with optimal prompt selection via bandit methods to refine evaluation accuracy.
RUBICON evaluates conversation quality for domain-specific assistants by developing rubrics for Satisfaction (SAT) and Dissatisfaction (DSAT) from labeled dialogues. The methodology includes generating diverse rubrics, selecting the most effective set, and scoring conversations. Rubrics, represented as natural language assertions, assess conversation attributes. Conversations are rated on a 5-point Likert scale, normalized to a [0, 10] range. The process involves supervised extraction and summarization for rubric generation, with selection focusing on precision and coverage. Correctness and sharpness losses guide optimal rubric selection, ensuring accurate assessment of conversation quality.
Key questions for evaluating RUBICON include its effectiveness relative to other methods, the influence of Domain Sensitization (DS) and Conversation Design Principles (CDP), and the performance of its selection policy. The data, from a C# Debugger Copilot assistant, was annotated by skilled developers, leading to a 50:50 train-test split. Metrics such as accuracy, precision, recall, F1 score, ΔNetSAT score, and Yield Rate were assessed. Results indicate RUBICON’s superiority over baseline methods in differentiating positive and negative conversations and precise classification, underscoring the significance of DS and CDP instructions.
Despite high inter-annotator agreement, internal validity may be compromised by the subjective nature of manually assigned ground truth labels. External validity is limited by the dataset’s specific focus on C# debugging, potentially affecting generalization. Construct validity issues include reliance on an automated scoring system and the conversion of Likert scale responses to a [0, 10] scale. Future research will explore alternative calculation methods for the NetSAT score. RUBICON has proven effective in enhancing rubric quality and differentiating conversation effectiveness, demonstrating its practical value in real-world applications.
Conclusion:
RUBICON represents a significant advancement in the evaluation of domain-specific Human-AI conversations. By addressing the limitations of traditional metrics and incorporating domain-specific cues, RUBICON offers a more precise and contextually relevant method for assessing conversational quality. This advancement is poised to enhance the effectiveness of AI systems in specialized fields, potentially setting a new standard for conversational AI evaluation. As businesses increasingly rely on domain-specific AI tools, the adoption of RUBICON could improve customer satisfaction and operational efficiency, reflecting its broader impact on the market for AI evaluation solutions.