
TL;DR:
- Researchers from the National University of Singapore and the Chinese University of Hong Kong present MinD-Video, an AI tool using fMRI data to recreate dynamic visual experiences.
- Non-invasive technologies like fMRI have limitations in capturing continuous visual experiences.
- MinD-Video utilizes an fMRI encoder and augmented stable diffusion model to reconstruct videos from brain data.
- The model achieves remarkable accuracy and outperforms prior methods by 49% in semantic metrics.
- MinD-Video shows promise in neuroscience and Brain-Computer Interface (BCI) research.
- The fusion of AI and neuroimaging has transformative potential for the market, opening new avenues for science and technology.
Main AI News:
In a groundbreaking leap forward, researchers from the esteemed National University of Singapore and the prestigious Chinese University of Hong Kong have unveiled a cutting-edge innovation called MinD-Video. This revolutionary AI tool harnesses the power of functional Magnetic Resonance Imaging (fMRI) data from the human brain to recreate dynamic visual experiences like never before.
Unlocking the secrets of human cognition has long fascinated scientists and visionaries alike. The allure of deciphering human vision from brain processes becomes all the more captivating when non-invasive technologies, such as fMRI, are brought into play. While significant progress has been achieved in reconstructing still images from non-invasive brain recordings, capturing continuous visual experiences akin to cinematic marvels has remained an elusive pursuit.
Nonetheless, researchers have faced formidable challenges in this quest. Non-invasive technologies, while capable, have limitations as they gather only a finite amount of data and are susceptible to external factors like noise. Moreover, the process of gathering neuroimaging data is both time-consuming and costly.
Despite these hurdles, the MinD-Video team has made remarkable headway, particularly in leveraging sparse fMRI-annotation pairs to learn useful fMRI features. They recognize that human visual experiences are ceaseless streams of ever-changing scenes, movements, and objects. However, the conventional fMRI captures the brain’s activity only in snapshots, making the restoration of dynamic visual experiences exceptionally challenging. The temporal resolution of fMRI is significantly lower compared to the standard video frame rate, presenting a fundamental barrier to achieving fluid and lifelike video reconstructions.
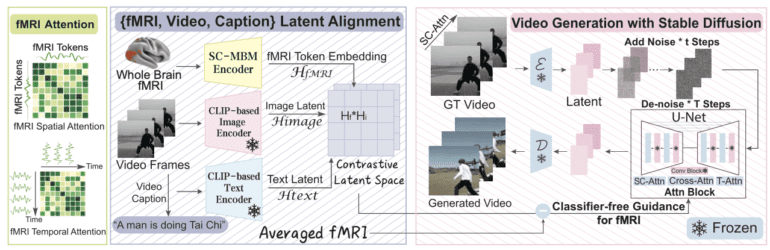
The researchers’ ingenious solution lies in MinD-Video—a modular brain decoding pipeline comprising an fMRI encoder and an augmented stable diffusion model. This powerful combination is trained independently and then fine-tuned together, gradually expanding its knowledge of the semantic landscape of the brain.
The MinD-Video process unfolds in several strategic stages. First, generic visual fMRI features are trained through extensive unsupervised learning and masked brain modeling. Then, leveraging the multimodal nature of the annotated dataset, the researchers distill semantic-related features and apply contrastive learning to train the fMRI encoder in the Contrastive Language-Image Pre-Training (CLIP) space. Additionally, an augmented stable diffusion model, purpose-built for video production using fMRI input, is co-trained with the learned features to refine and enhance them further.
One of the remarkable advancements of MinD-Video is its near-frame focus feature within the stable diffusion model. This innovation enables the generation of scene-dynamic videos with striking realism. Moreover, the team has developed an ingenious adversarial guidance system that allows for the precise conditioning of fMRI scans to achieve specific objectives.
The outcomes of MinD-Video have been nothing short of astounding. The generated videos exhibit high-quality visuals, with seamless semantics, motions, and scene dynamics that match human experiences with astonishing accuracy. Quantitative assessments have validated the excellence of MinD-Video, achieving an 85% accuracy in semantic metrics and an impressive 0.19 in Structural Similarity Index (SSIM). This groundbreaking method outperforms the prior state-of-the-art approaches by an impressive 49%.
Beyond its remarkable performance, MinD-Video showcases hints of biological plausibility and interpretability, as confirmed by the results of attention studies. The model has been shown to effectively map to the visual cortex and higher cognitive networks, suggesting a remarkable connection between AI and the complexities of the human brain.
While the potential of MinD-Video is evident, the researchers remain diligently cautious about its generalizability across different subjects. They acknowledge that this cutting-edge technique utilizes less than 10% of cortical voxels for reconstructions, leaving vast untapped potential in the wealth of brain data. As MinD-Video evolves with more sophisticated models, its applications may extend to diverse fields, including neuroscience and Brain-Computer Interface (BCI) research.
Conclusion:
MinD-Video represents a significant breakthrough in AI and neuroimaging, revolutionizing how we recreate and understand human visual experiences. This advancement holds immense promise for various industries, from neuroscience research to the development of cutting-edge Brain-Computer Interface technologies. As the market witnesses the fusion of AI and brain decoding, we can anticipate transformative applications and groundbreaking opportunities for innovation and growth.