
- MoDE, or Mixture of Data Experts, is a novel approach for enhancing vision-language models.
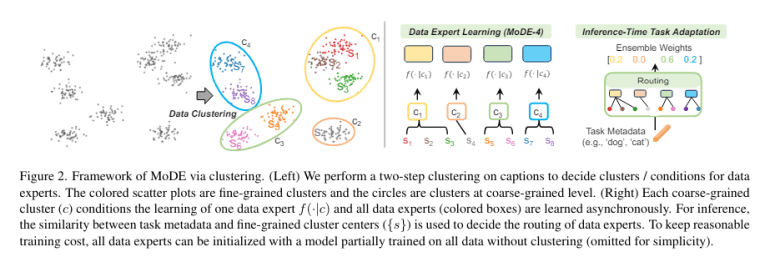
- It segments training data into clusters and assigns dedicated ‘data experts’ to each cluster.
- Each data expert specializes in its assigned cluster, mitigating noise and improving model performance.
- During inference, outputs from different data experts are combined based on task metadata.
- MoDE-equipped models consistently outperform existing state-of-the-art models across various benchmarks.
- Significant performance gains are observed in zero-shot image classification and retrieval tasks.
- MoDE achieves these improvements while utilizing fewer training resources than traditional models.
Main AI News:
In the realm of vision-language representation, the quest for innovative methodologies persists in bridging the gap between textual and visual inputs, a crucial pursuit facilitating machine comprehension of the ever-expanding digital content landscape. Despite strides made, challenges persist, primarily stemming from the inherent noise prevalent in internet-sourced data, where mismatches between image-caption pairs hinder model accuracy during training.
Enter MoDE, a groundbreaking approach pioneered by researchers from FAIR at Meta, alongside esteemed institutions like Columbia University, New York University, and the University of Washington. MoDE, short for Mixture of Data Experts, represents a paradigm shift in handling noisy datasets. Departing from conventional techniques that employ a unified model for training across all data, MoDE adopts a novel strategy: assigning dedicated ‘data experts’ to distinct clusters within the dataset. This expert-based segmentation enhances the model’s resilience against noise, fostering improved performance in disparate segments of the data.
MoDE’s methodology unfolds in two pivotal stages. Initially, the dataset, comprising image-caption pairs, undergoes clustering based on semantic affinity, ensuring each cluster encapsulates closely related instances. Subsequently, each cluster trains an individual data expert utilizing established contrastive learning methodologies. This tailored approach empowers each expert to glean nuanced insights specific to its assigned cluster, shielded from the interference of noise originating from unrelated segments.
The operational prowess of MoDE shines during the inference phase, where outputs from diverse data experts converge. This ensemble isn’t arbitrary; rather, it’s guided by task metadata, aligning with the unique characteristics of each cluster. For instance, in image classification tasks, alignment between class names and cluster centroids informs the selection of the most pertinent data expert, thereby refining the precision of the model’s predictions.
Benchmark assessments underscore MoDE’s superiority over existing vision-language models. Particularly noteworthy is its performance in zero-shot image classification tasks, where MoDE-equipped models, leveraging a ViT-B/16 architecture, exhibit performance gains of up to 3.7% compared to traditional counterparts like OpenAI CLIP and OpenCLIP, all while consuming less than 35% of the training resources typically required. Moreover, MoDE showcases substantial enhancements in image-to-text and text-to-image retrieval tasks across datasets such as COCO, boasting recall metric improvements exceeding 3% vis-a-vis baseline models.
Conclusion:
The introduction of MoDE represents a significant advancement in the field of vision-language models, offering enhanced accuracy and efficiency in processing textual and visual data. This innovation holds great promise for industries reliant on machine comprehension, such as e-commerce, media, and autonomous systems, where improved model performance can drive better user experiences and operational efficiency. Embracing MoDE-inspired methodologies could pave the way for transformative developments in a wide array of applications, propelling businesses towards greater competitiveness and innovation.